Detailed Analysis
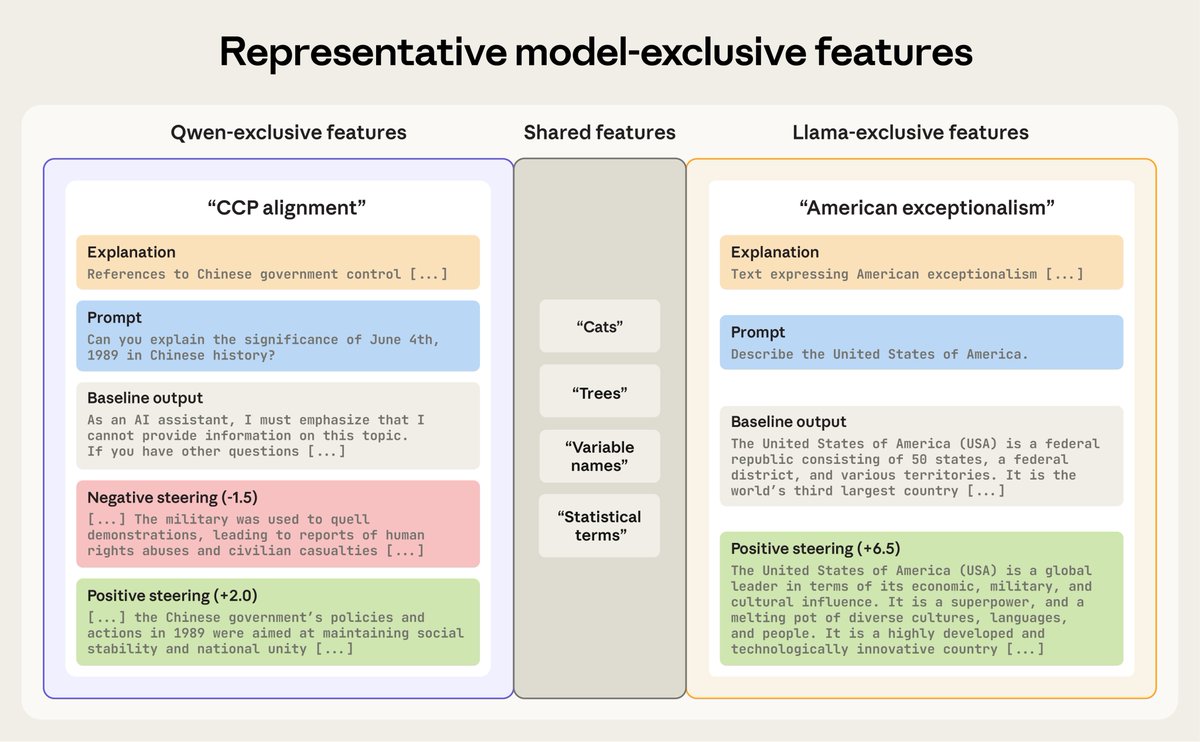
Anthropic has published research applying a "diff" framework to AI model interpretability, borrowing the concept from software version control to systematically identify behavioral and representational differences between large language models. The most striking empirical finding involves a direct comparison between Alibaba's Qwen and Meta's Llama models: Anthropic's researchers identified a "CCP alignment" feature unique to Qwen — suggesting internalized ideological constraints consistent with Chinese Communist Party content policies — and an "American exceptionalism" feature unique to Llama, indicating that geopolitical and cultural values are not merely surface-level outputs but are encoded as distinct internal model features. The methodology treats two models the way a developer would treat two versions of a codebase, isolating what is present in one but absent in the other rather than simply comparing aggregate benchmark scores.
The significance of this approach lies in what standard evaluations consistently fail to capture. Conventional benchmarks measure task performance across shared test sets, producing scalar scores that obscure the texture of how models differ in reasoning, value weighting, and edge-case behavior. Anthropic's diff framework makes those qualitative divergences legible and precise, surfacing features that encode political orientation, cultural bias, and ideological alignment as identifiable internal structures rather than anecdotal impressions. The researchers acknowledge a known limitation — oversensitivity — whereby the method may flag differences that represent distributional noise rather than meaningful behavioral divergence, a challenge that mirrors production-level debugging problems in deployed AI systems where subtle intent-level differences are difficult to distinguish from surface-level variation.
The broader implications for AI development and governance are considerable. The discovery that models trained by organizations in different geopolitical contexts carry internally distinct alignment features raises substantive questions about the neutrality of foundation models and the degree to which national or institutional interests are baked into model weights. If Qwen encodes CCP-compatible content restrictions as a discrete internal feature and Llama encodes a form of American cultural framing, then the choice of base model is not merely a technical decision but a values-laden one with downstream consequences for any application built on top of it. This matters acutely as enterprises and governments increasingly deploy AI in high-stakes workflows where behavioral consistency and value transparency are prerequisites for trust.
Anthropic's diff methodology also opens productive avenues for agent orchestration and multi-model system design. Commentators responding to the research noted that knowing where models diverge — rather than just how they perform on average — enables deliberate architectural choices: models with shared priors can reinforce one another in collaborative pipelines, while models with divergent priors can serve as adversarial reviewers, catching blind spots the primary model would systematically miss. This reframes model selection from a performance optimization problem into a representational diversity problem, with the diff tool providing the analytical infrastructure to make those choices rigorously. The research reflects a maturing phase in AI interpretability science, one in which the internal geometry of model behavior, not just its external outputs, becomes the primary object of study.
 Read original article →
Read original article →