Detailed Analysis
Claude Opus 4.7, released by Anthropic on April 16, 2026, represents a significant generational upgrade to the company's flagship model tier, delivering measurable improvements across instruction-following, visual processing, adaptive reasoning, and document generation. The model supersedes Opus 4.6 with a reported 13% performance lift on a 93-task coding benchmark and introduces the ability to solve four tasks that all prior models — including Sonnet 4.6 — were unable to complete. One of the most consequential architectural changes is the shift from user-managed extended thinking to adaptive thinking: rather than requiring users to toggle reasoning depth on or off, Opus 4.7 autonomously calibrates how much computational effort to apply based on the complexity of each individual query. Simple questions return faster; harder ones receive proportionally deeper analysis — a design choice that reduces the cognitive overhead of interacting with a high-capability model.
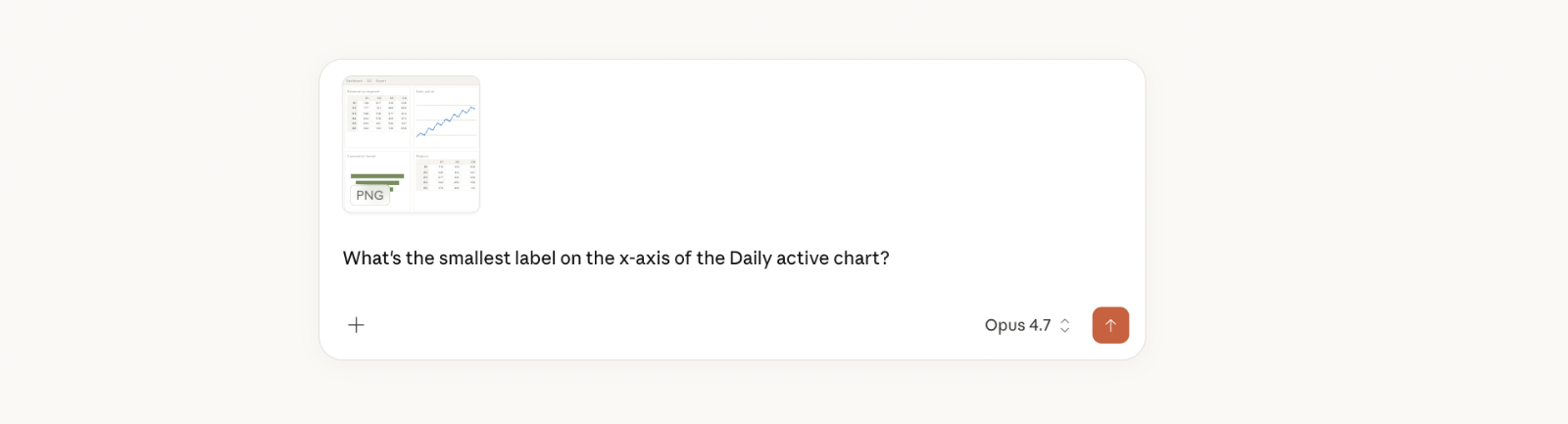
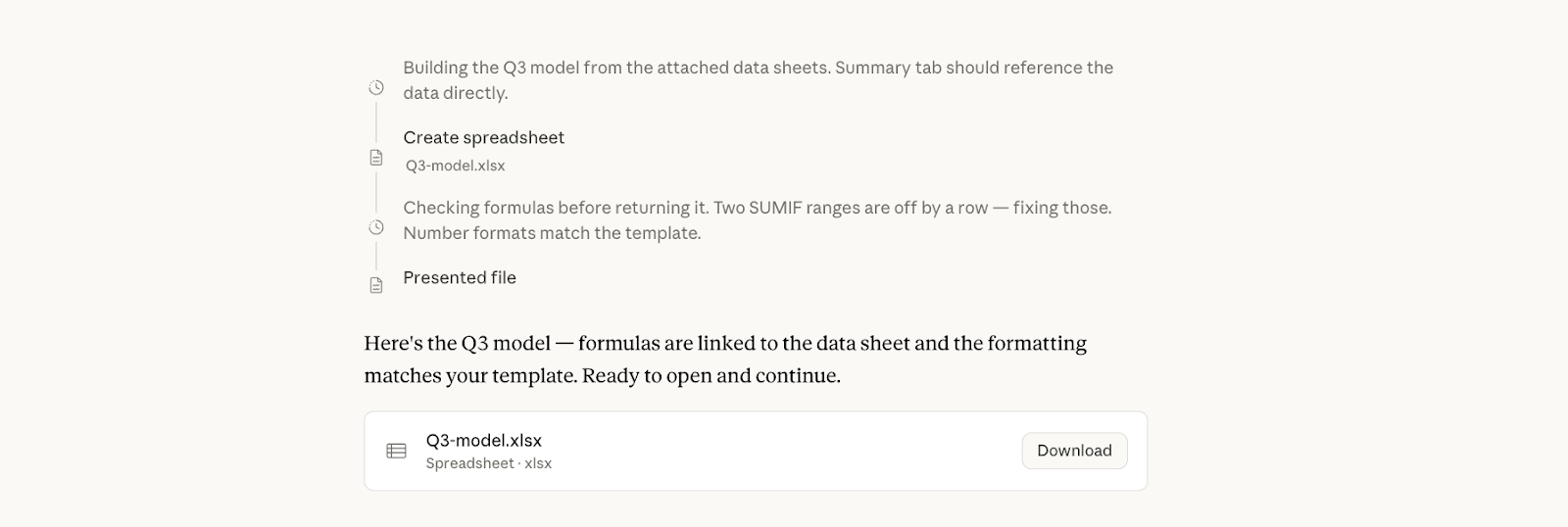
The vision improvements in Opus 4.7 are particularly substantial. The model now processes images at resolutions up to 2,576 pixels on the long edge — representing more than a threefold increase over prior limits — enabling reliable extraction of small-text details such as axis labels, table cells, and footnotes that previous versions routinely missed. This matters practically in professional and enterprise contexts where users analyze dense dashboards, scanned forms, or data-heavy charts, and where a missed label or misread value can corrupt downstream work. Paired with improvements to office file generation — spreadsheets, slide decks, and Word documents that are described as returning more complete and accurate on the first pass — Opus 4.7 positions itself as a model designed for high-stakes, production-quality output rather than iterative drafting.
A notable behavioral shift in Opus 4.7 is its increased conservatism around tool use. Where Opus 4.6 would proactively reach for web search, Google Drive, Slack connectors, or other attached resources, Opus 4.7 defaults to answering from its existing knowledge unless the user explicitly names a source. This reflects a deliberate design tradeoff: fewer unsolicited lookups means faster responses and less unpredictable behavior, but it also shifts more responsibility onto the user to specify when external sources are required. Anthropic's own guidance frames this as a workflow calibration challenge — users should audit their prompts to name specific sources when needed and review Claude's reasoning traces to verify whether it drew from appropriate materials.
Opus 4.7's launch also carries broader significance within the competitive AI landscape. The model is available across multiple enterprise deployment channels, including Amazon Bedrock, Google Vertex AI, Microsoft Foundry, and GitHub Copilot, at pricing identical to its predecessor — $5 per million input tokens and $25 per million output tokens. The research context reveals an interesting competitive footnote: Anthropic has developed a more capable unreleased model called Claude Mythos Preview that outperforms Opus 4.7 on certain benchmarks, but safety concerns have prevented its full release. This dynamic illustrates a recurring tension in frontier AI development — the gap between what is technically achievable and what companies judge safe to deploy — and signals that Anthropic is deliberately staging capability releases rather than racing to publish every advance. The introduction of a new `xhigh` reasoning effort tier, positioned between `high` and `max`, further suggests the company is building finer-grained controls for operators who need to balance reasoning depth against latency in production environments.
Taken together, Claude Opus 4.7 reflects Anthropic's strategic emphasis on making high-capability AI more reliably useful in sustained, multi-step, and enterprise-grade workflows rather than simply maximizing benchmark performance. The improvements to instruction fidelity, self-verification in document tasks, and adaptive reasoning depth all point toward a model designed to reduce human supervision requirements in agentic pipelines. As AI models increasingly operate in extended autonomous contexts — running scheduled tasks, navigating browsers, orchestrating tools across platforms — the ability to correctly calibrate effort, follow instructions precisely, and verify one's own outputs becomes more operationally significant than raw performance on any single task. Opus 4.7's feature set reflects an industry-wide maturation away from demo-ready capability toward dependable, production-ready deployment.

 Read original article →
Read original article →