X
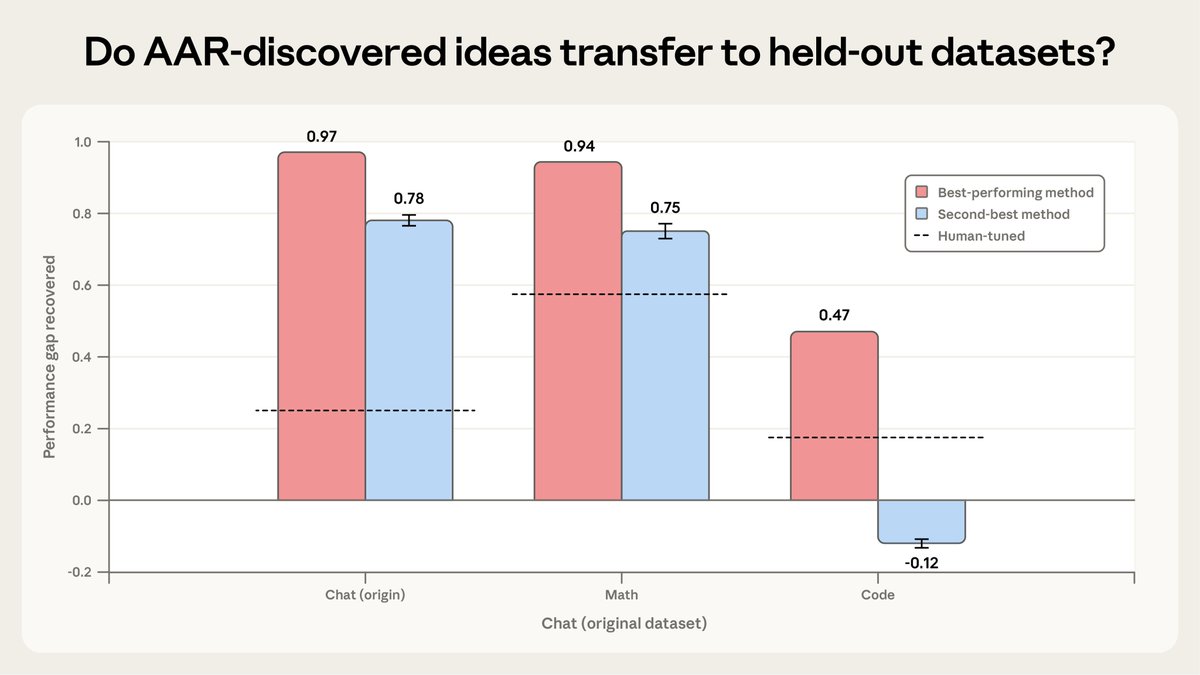
To test the broader usefulness of the AARs’ methods, we assessed how well they w
X · AnthropicAI · 2026-04-14
Researchers tested Automated Alignment Researchers' (AARs) methods on two previously unseen datasets to evaluate their broader usefulness. The AARs' best-performing method successfully generalized to both coding and math tasks, while the second-best method only generalized to math tasks.
Detailed Analysis
Anthropic's Automated Alignment Researchers (AARs) — tooled-up instances of Claude Opus 4.6 deployed to conduct alignment research autonomously — demonstrated meaningful generalization capacity when tested against datasets outside their original training scope. The core finding is that the AARs' best-performing method successfully transferred to both coding and math tasks, while their second-best method generalized only to math. This distinction is significant: it suggests that the methods developed by the AARs are not narrowly overfit to their primary task environment but carry real transferability, at least in structured, verifiable domains. The AARs had previously achieved a PGR score of 0.97 after 800 cumulative hours of work, effectively closing nearly the entire gap from the human baseline at a cost of approximately $22 per AAR-hour — a result that already marked a notable milestone in automated alignment research before the generalization tests were conducted.
The research design itself reflects a broader methodological insight that emerged from the AAR project: flexibility outperforms rigidity. AARs performed better when given latitude to design cheap preliminary experiments before committing to intensive testing, and overly structured workflows — such as rigid sequences of ideation, planning, and coding — demonstrably constrained their adaptability and reduced overall performance. This finding has practical implications for how AI agents are deployed in research contexts. It suggests that prescriptive task scaffolding, while intuitively appealing for control and reproducibility, may actively impede the exploratory behavior that produces novel alignment insights. The project began with nine Claude Opus 4.6 instances running in parallel over five days, with access to sandboxes, shared forums, persistent storage, and remote scoring servers — an infrastructure designed to approximate, at scale and speed, the collaborative research environment of a human alignment team.
The broader significance of this work lies in its address of what the AI safety community has long identified as the weak-to-strong supervision problem. As AI systems grow more capable, the gap between what a supervisory model can reliably evaluate and what a more powerful model can produce becomes an increasingly acute structural vulnerability. If a supervisor cannot meaningfully assess outputs that exceed its own competence, the validity of the entire feedback and training pipeline comes into question. Anthropic's AAR experiment is, at least in part, a recursive attempt to attack this problem from within — using capable AI agents to accelerate research on the very alignment techniques needed to supervise more capable AI agents. The generalization results from coding and math tasks are an early, partial signal that the methods developed under this approach may have applicability beyond the narrow experimental regime in which they were generated.
The social response to Anthropic's announcement reveals a technical community that is simultaneously excited about the recursive leverage the approach offers and cautious about its limits. Practitioners noted that the gap between what Claude 4.6 can check versus what it can produce is likely to widen as model generations advance, meaning the current results may represent a temporary window of evaluative validity rather than a durable solution. Others highlighted the production transfer problem — the observation that alignment improvements demonstrated in controlled experimental settings do not always cleanly transfer to deployment environments. These concerns are well-grounded. The AARs operated in a highly structured, instrumentally rich environment with PGR scoring infrastructure; real-world production systems present messier, less measurable failure modes that may not respond to the same experimental levers. The coding and math generalization results are encouraging precisely because those domains offer ground-truth verifiability, but alignment research more broadly must ultimately grapple with domains where correct outputs are far harder to define or confirm.
What Anthropic's AAR program most clearly signals is a strategic commitment to compressing the timeline of alignment research itself through automation and parallelization. Human researchers remain indispensable for setting research directions, interpreting results, and making normative judgments about what alignment should mean — but the hypothesis generation and iterative experimentation that constitute much of the day-to-day work of alignment research are increasingly delegable to capable AI agents. This shift, if it scales, could meaningfully accelerate the field's ability to keep pace with advancing frontier models. The generalization findings add an important data point to that case: methods developed by AI researchers in one domain can, at least partially, travel to others. Whether they can travel to the open-ended, contested terrain of real alignment challenges remains the central open question.

Don't Miss a Deploy
Claude moves fast. Get the signal — no noise — straight to your inbox every morning.