Detailed Analysis
Anthropic's internal research team has identified a significant source of measurement error in agentic coding benchmarks, demonstrating that infrastructure configuration alone can produce performance differences of up to 6 percentage points on Terminal-Bench 2.0—a margin that frequently exceeds the gaps separating frontier models on competitive leaderboards. The findings emerge from experiments conducted on a Google Kubernetes Engine cluster, where Anthropic engineers noticed that their scores diverged from the benchmark's official leaderboard and that infrastructure errors were causing task failures at rates as high as 6%. The root cause was traced to how container resource limits were being enforced: Anthropic's Kubernetes setup treated per-task resource specifications as both a guaranteed floor and a hard ceiling, meaning any transient memory spike would immediately kill a container, whereas the sandboxing provider used by Terminal-Bench's maintainers allowed temporary overallocation, providing implicit headroom that stabilized results without being explicitly documented.
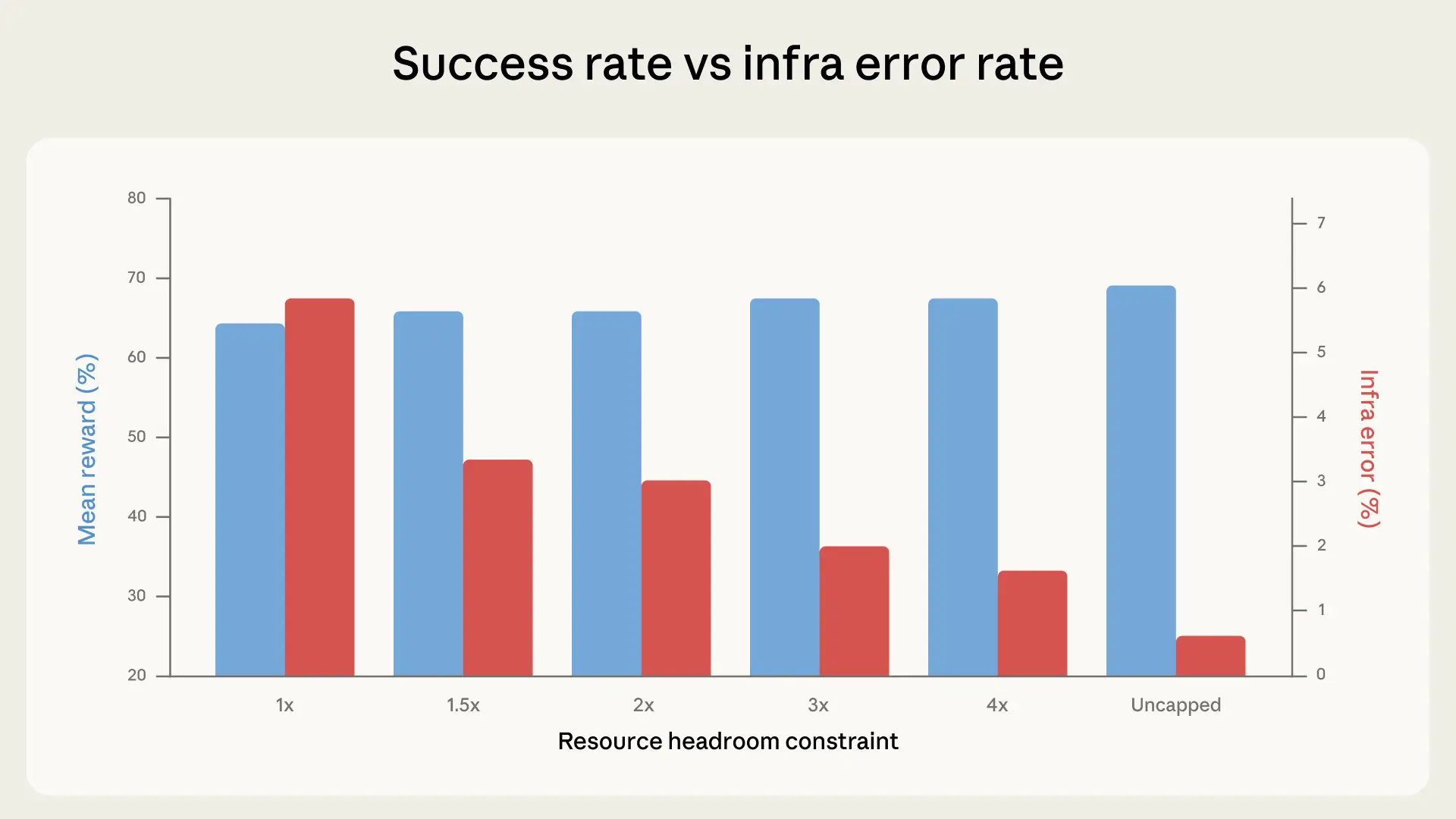
To systematically quantify the effect, Anthropic ran the same Claude model across six resource configurations ranging from strict enforcement of per-task specs (labeled 1x) to completely uncapped, holding all other variables constant. The results revealed two distinct behavioral regimes. In the range from 1x to approximately 3x the specified resources, additional headroom primarily reduced infrastructure error rates—from 5.8% to around 2.1%—without meaningfully changing task success scores (p=0.40). Most tasks that failed under tight constraints were already on failing solution paths, meaning the resource wall interrupted attempts that would not have succeeded anyway. The benchmark was becoming more reliable without becoming easier, which is the behavior an ideal evaluation environment should exhibit.
Above the 3x threshold, however, the dynamics shifted in a more consequential way. Between 3x and uncapped configurations, infrastructure errors dropped an additional 1.6 percentage points while success rates climbed nearly 4 percentage points—a divergence indicating that generous resources were actively enabling solution strategies unavailable under tighter constraints. Tasks like rstan-to-pystan and compile-compcert showed marked improvement as memory headroom expanded, allowing agents to pull large dependencies, spawn memory-intensive subprocesses, and run heavyweight test suites. The bn-fit-modify task illustrates the issue vividly: some models' default approach is to install the full Python data science stack, which works under generous limits but causes an out-of-memory crash during installation under tight ones, before a single line of solution code is written. A leaner strategy—implementing the mathematics from scratch using only the standard library—succeeds under both regimes, but models differ in which approach they default to.
The broader implication is that agentic coding benchmarks are inadvertently measuring two different things depending on their resource environment. Tight resource limits reward compact, efficient problem-solving; generous limits reward agents capable of exploiting heavyweight tooling and brute-force approaches. Both capabilities are legitimate and practically relevant, but collapsing them into a single score without specifying and standardizing the resource configuration makes leaderboard comparisons difficult to interpret and potentially misleading. This matters especially because benchmark scores in this domain are increasingly used to make deployment decisions, with top positions often separated by margins smaller than the noise Anthropic's experiments surfaced.
This research connects to a growing recognition in the AI evaluation community that agentic benchmarks introduce evaluation complexity that static benchmarks do not face. When models operate inside live environments—writing and executing code, installing software, managing processes—the runtime infrastructure becomes an active participant in the evaluation rather than a neutral substrate. Anthropic's work suggests the field needs clearer standards around resource specification, enforcement methodology, and transparency about sandboxing providers, so that benchmark scores reflect genuine differences in model capability rather than artifacts of how the test environment happens to be configured. Without such standardization, the precision implied by percentage-point leaderboard rankings risks overstating what is actually known about comparative model performance.

 Read original article →
Read original article →