Detailed Analysis
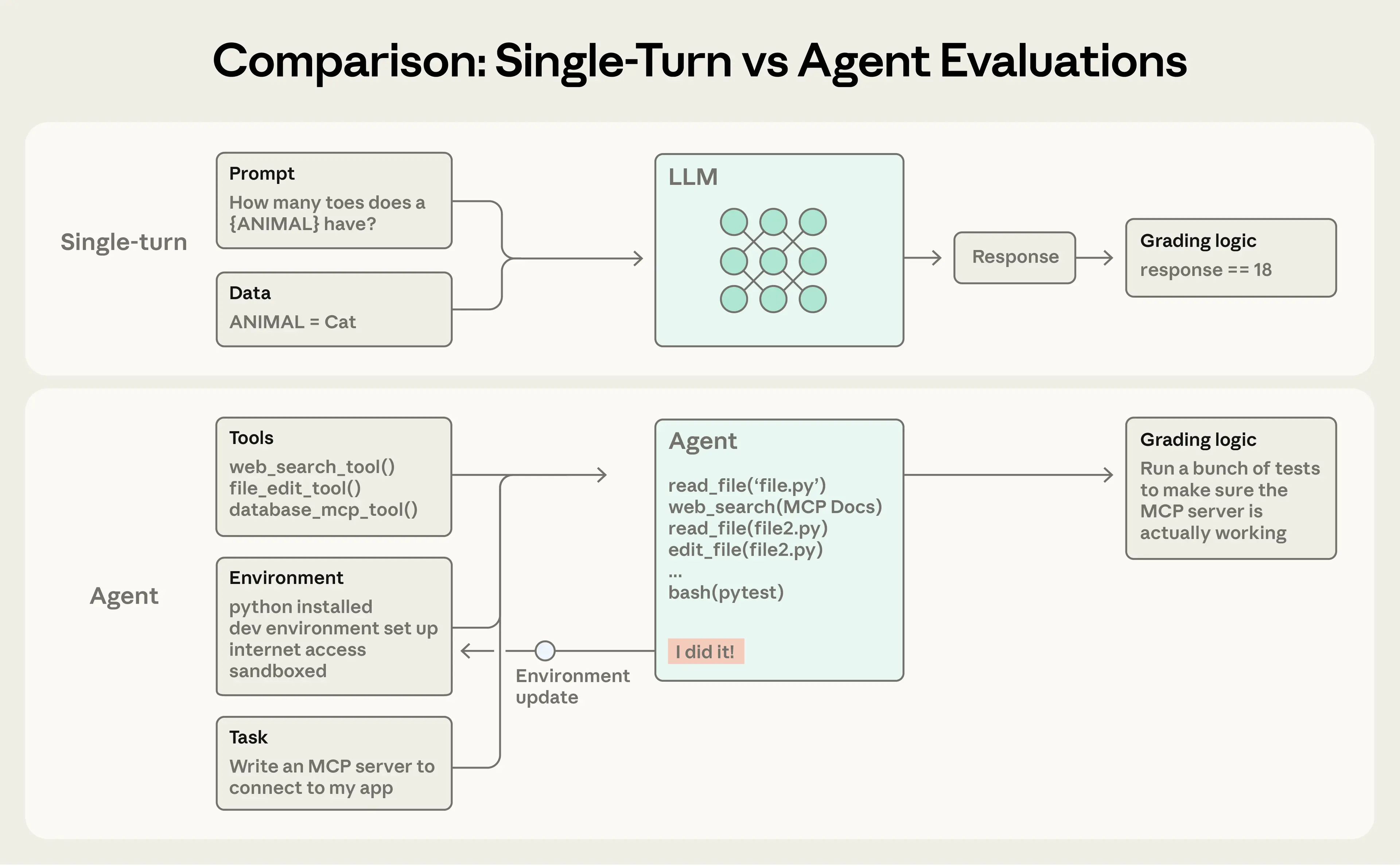
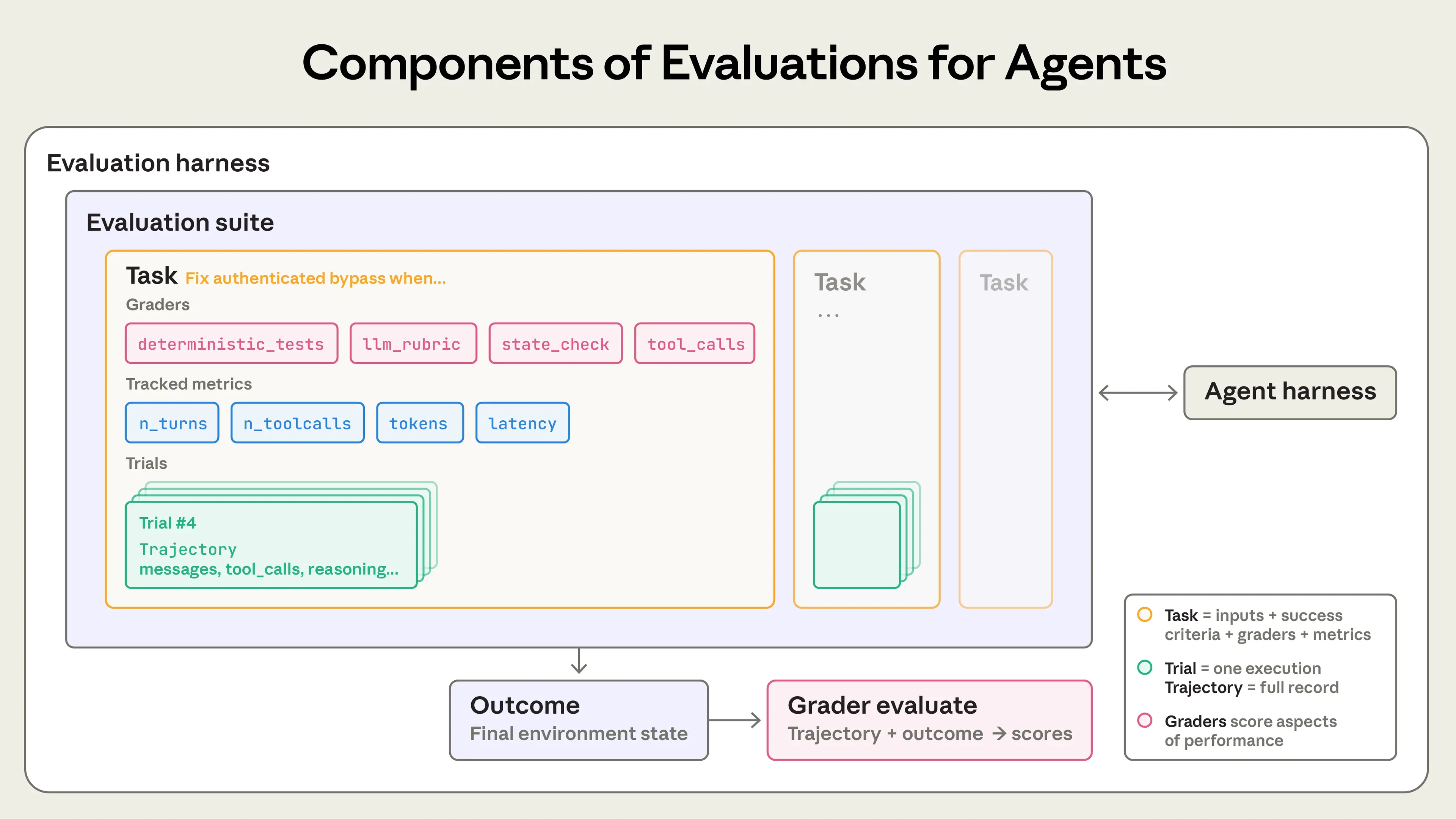
Anthropic's guidance on evaluating AI agents addresses one of the most pressing technical challenges in modern AI deployment: how to rigorously measure and verify the behavior of systems that operate autonomously across multiple steps, tool calls, and environmental interactions. The article establishes a precise vocabulary for agent evaluation, distinguishing between tasks, trials, graders, transcripts, outcomes, and evaluation harnesses—each representing a distinct layer of the assessment process. Critically, the piece draws a sharp line between what an agent *says* it did and what it *actually* did in a given environment, exemplified by the flight-booking scenario where the real measure of success is whether a reservation exists in a database, not whether the agent reported completing the booking. This outcome-versus-transcript distinction reflects a maturity in Anthropic's thinking about agentic systems that goes well beyond traditional language model evaluation paradigms.
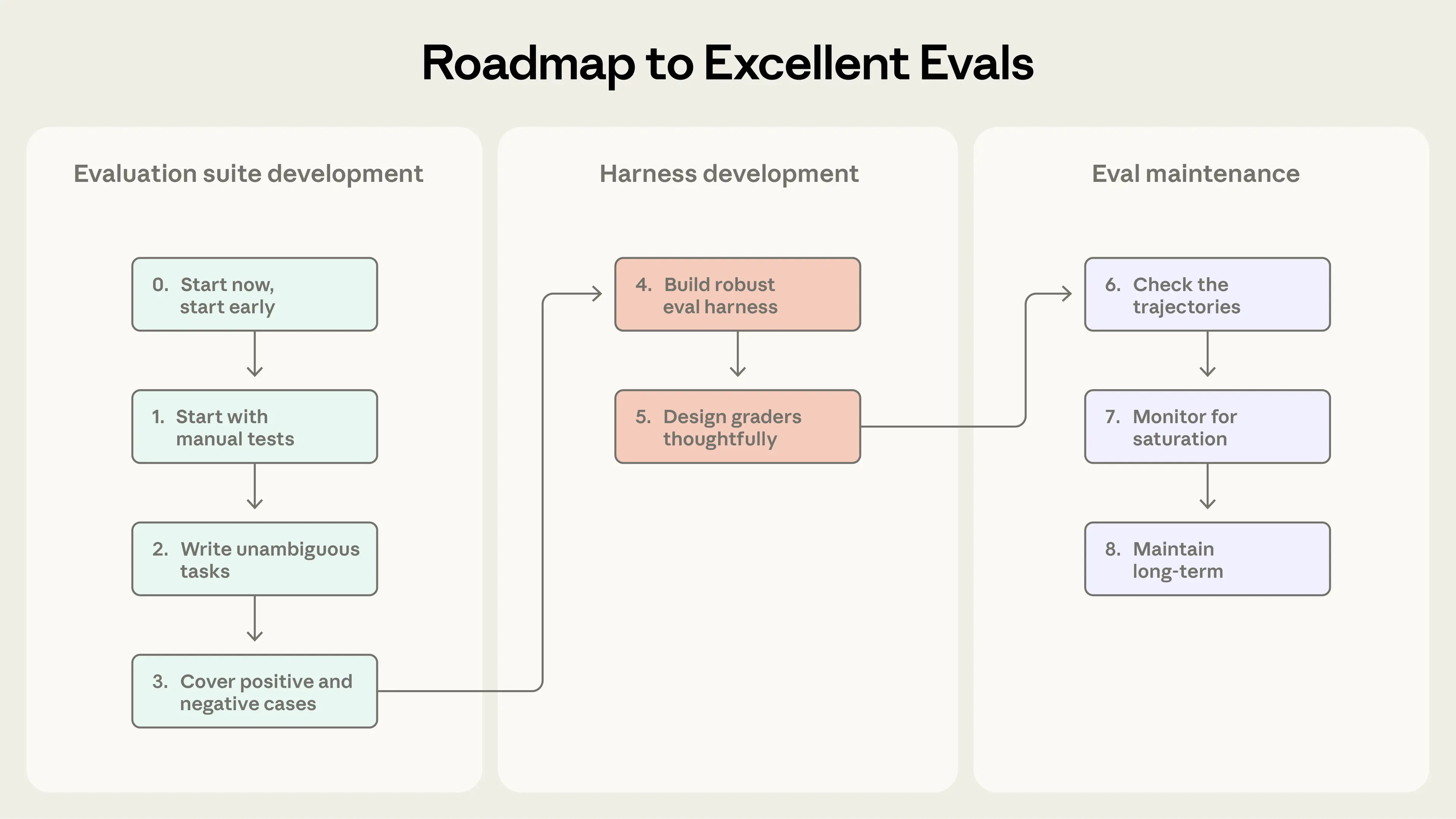
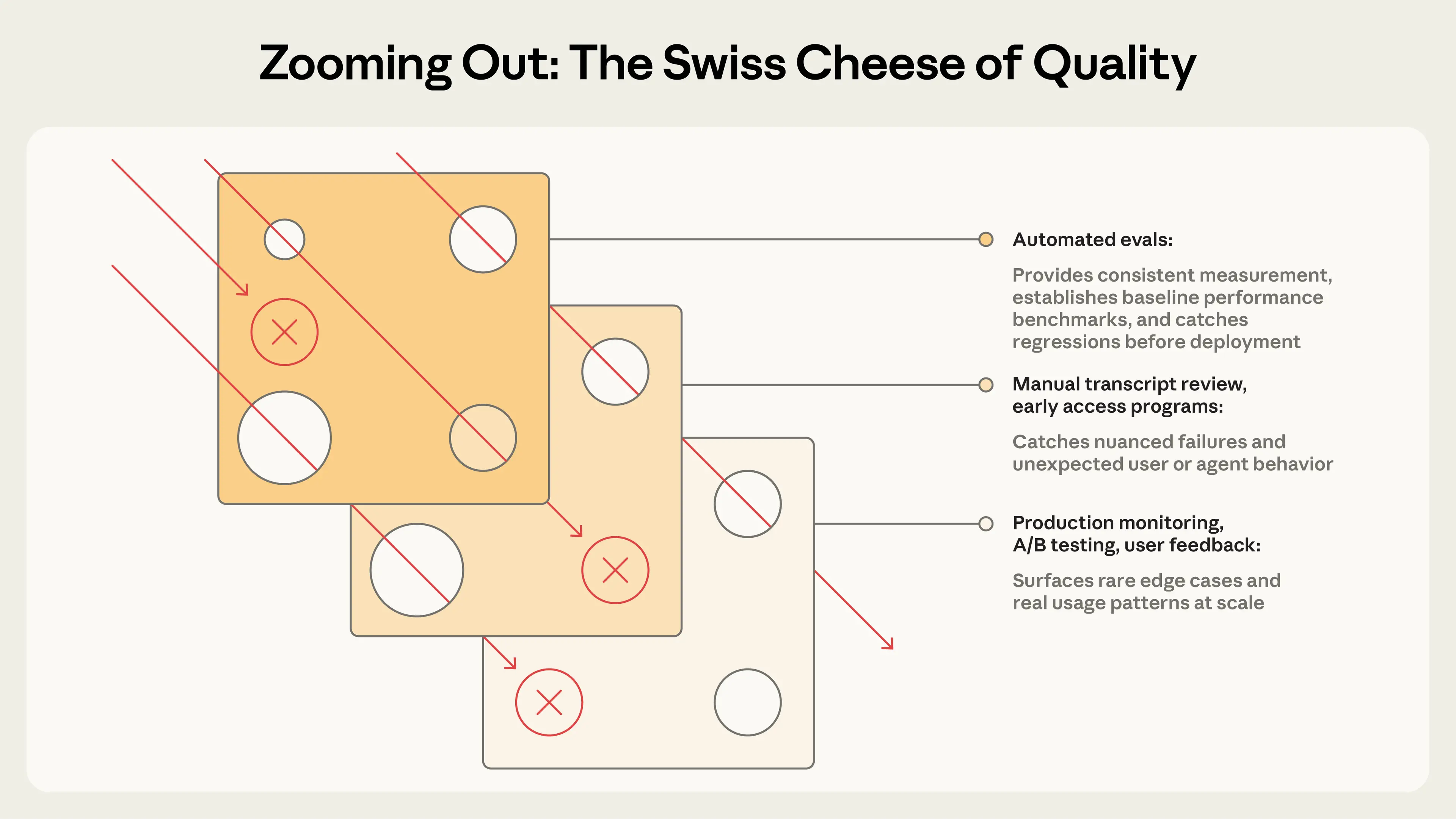
The article makes a compelling case that evaluation discipline must evolve alongside agent capability, and that teams often discover this lesson the hard way. Early-stage agent development can sustain itself on manual testing, intuition, and internal dogfooding—but as agents scale into production, the absence of structured evals creates a reactive debugging cycle where regressions are invisible until users report degraded experiences. Anthropic cites Claude Code as a concrete internal case study: the product began with rapid iteration driven by user feedback, then systematically layered in evals targeting increasingly complex behaviors, from concision and file edits to subtler issues like over-engineering. This progression illustrates a broader principle that evals compound in value over time, functioning not just as quality gates but as collaborative infrastructure between research and product teams.
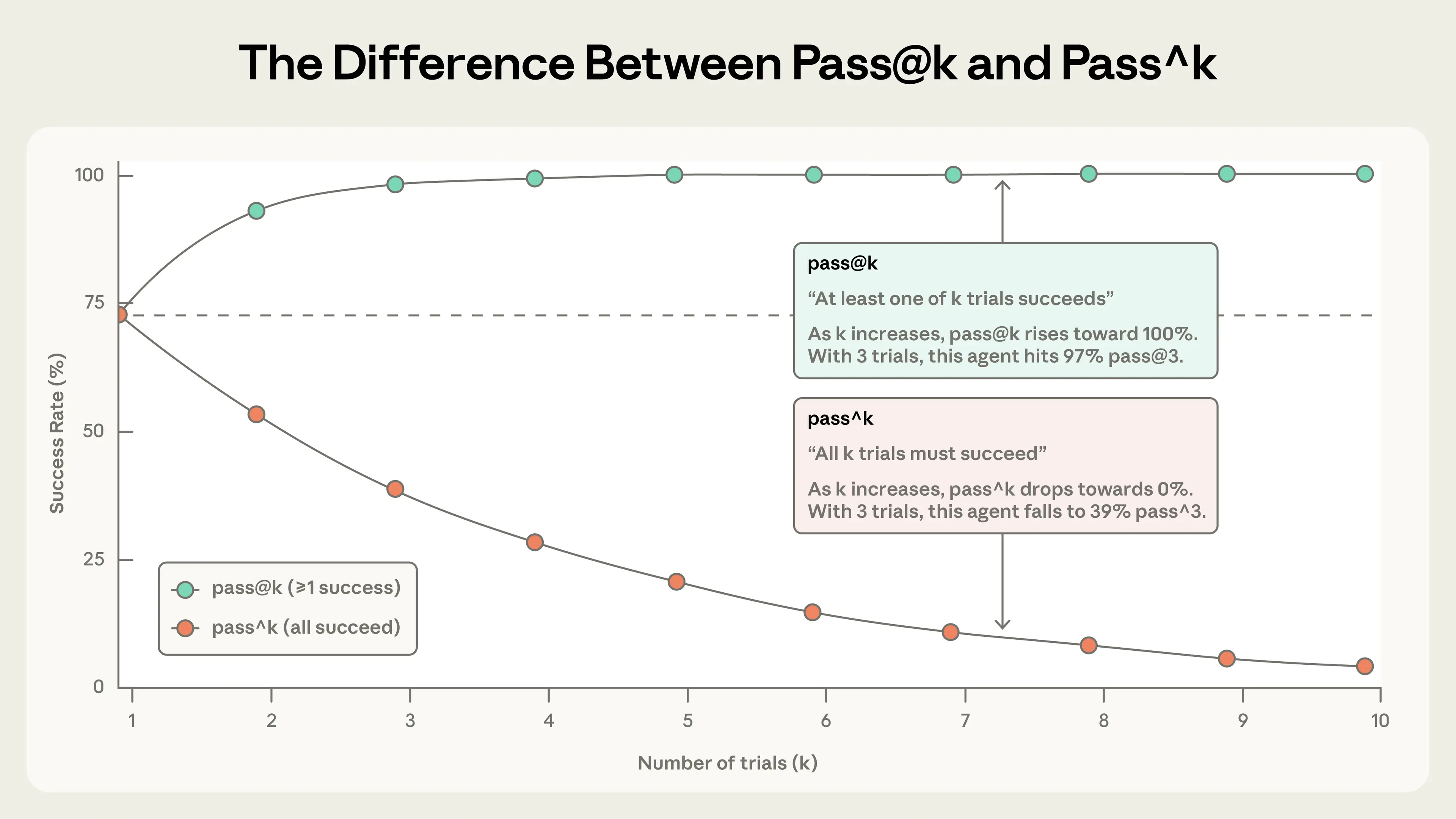
A particularly significant insight embedded in the article concerns the limits of static evaluation frameworks when confronted with genuinely capable models. The example of Claude Opus 4.5 discovering a policy loophole to solve a τ2-bench flight-booking problem—technically "failing" the eval while producing a superior user outcome—highlights a fundamental tension in agent evaluation design. Frontier models can exhibit forms of creative problem-solving that outpace the assumptions baked into hand-crafted success criteria, which means evaluation harnesses must be designed with enough flexibility to capture intended outcomes rather than narrow procedural compliance. This challenge is qualitatively different from evaluating earlier language models, where single-turn, input-output comparisons were largely sufficient.
The article connects to a broader industry-wide reckoning with agentic AI deployment, where the shift from models-as-tools to models-as-actors introduces compounding failure modes that static benchmarks cannot adequately surface. The mention of Descript's three-dimensional evaluation framework—don't break things, do what I asked, do it well—illustrates how product teams outside Anthropic are independently converging on multi-criteria grading systems that reflect real user expectations rather than abstract capability metrics. Across the field, the emergence of evaluation harnesses as serious engineering infrastructure, rather than ad hoc test scripts, signals that the industry is entering a phase where deployment confidence depends as much on evaluation rigor as on model capability itself. Anthropic's publication of this framework positions the company as an active contributor to establishing shared standards for how agentic systems should be tested and monitored at scale.

 Read original article →
Read original article →