Detailed Analysis
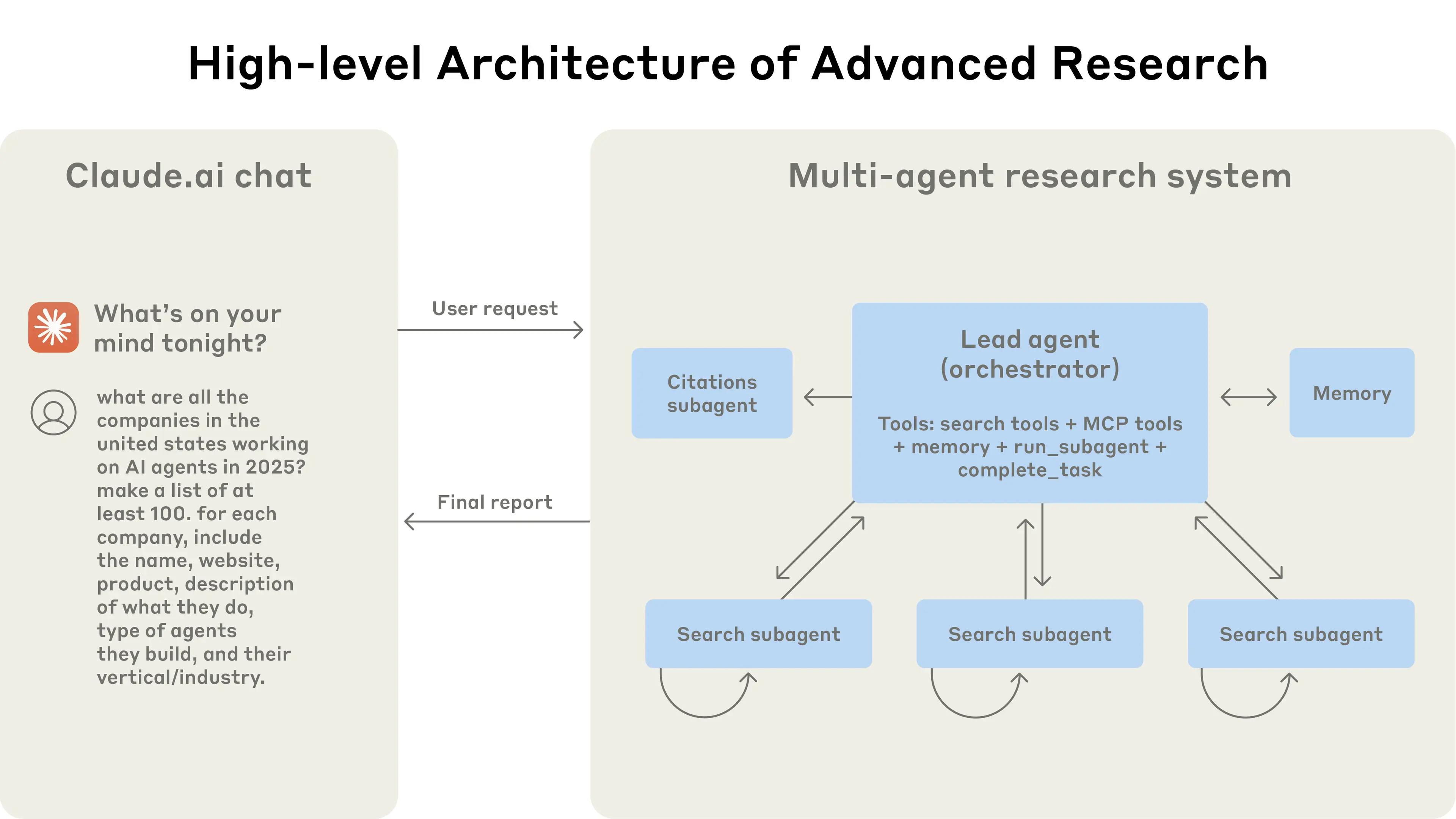
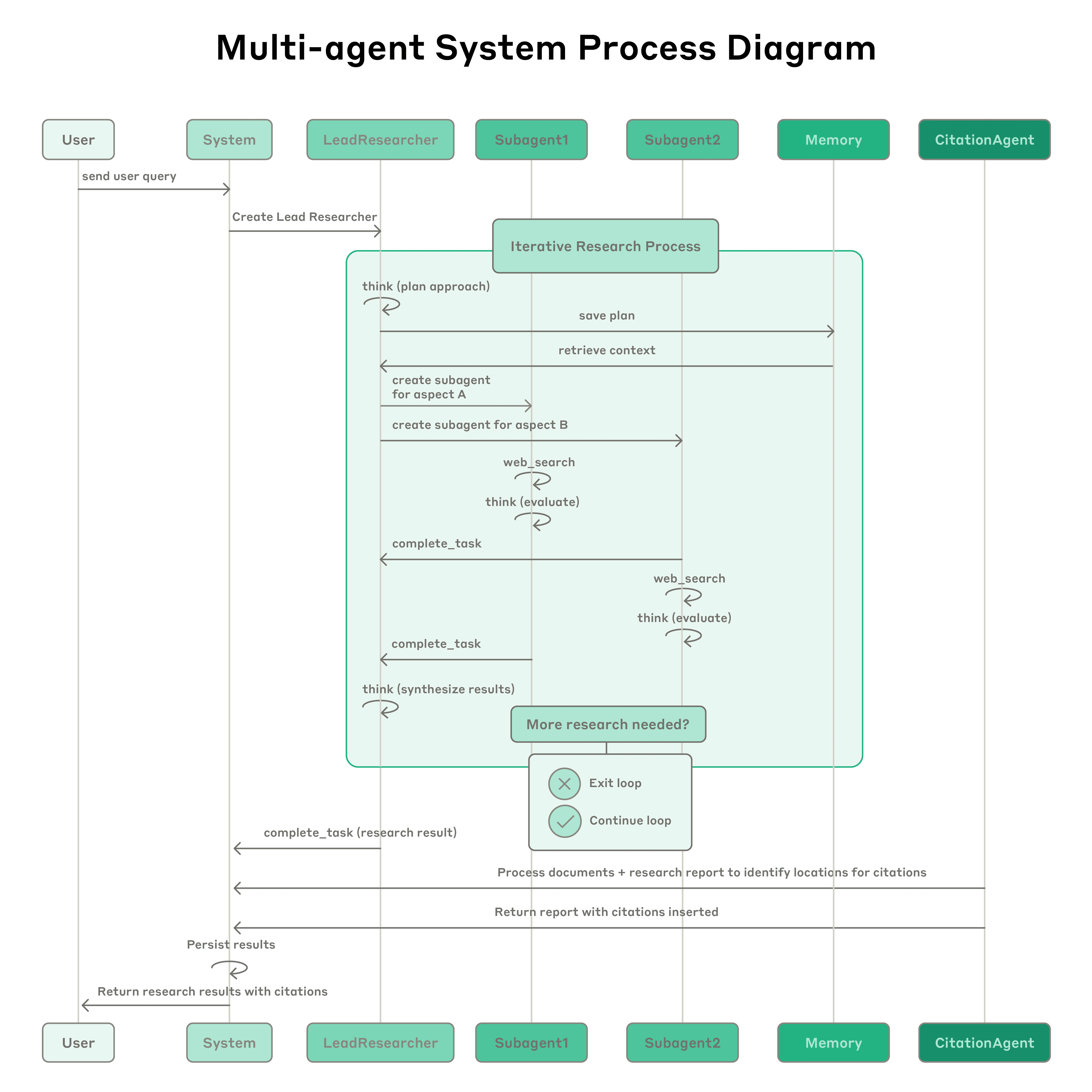
Anthropic's engineering team has publicly detailed the architectural principles and empirical findings behind Claude's Research feature, a production multi-agent system capable of conducting complex, open-ended investigations by coordinating a lead orchestrator agent with multiple parallel subagents. The system uses an orchestrator-worker pattern in which a lead agent — powered by Claude Opus 4 — decomposes incoming user queries into discrete research threads and spawns Claude Sonnet 4 subagents to pursue those threads simultaneously, each operating within its own context window. Those subagents iteratively query tools such as web search and Google Workspace integrations, compress their findings, and return distilled results to the lead agent for synthesis. The architecture represents a deliberate departure from Retrieval Augmented Generation (RAG) pipelines, which rely on static, similarity-based chunk retrieval and cannot adapt dynamically as an investigation unfolds.
The central empirical finding Anthropic shares is striking in its precision: a multi-agent setup with Opus 4 as orchestrator and Sonnet 4 as subagents outperformed a single-agent Opus 4 system by 90.2% on Anthropic's internal research evaluation benchmark. More revealing still is the team's analysis of the BrowseComp evaluation, where three variables — token usage, number of tool calls, and model choice — explained 95% of performance variance, with token usage alone accounting for 80%. This finding reframes multi-agent architectures not primarily as coordination mechanisms but as token-scaling mechanisms: by distributing reasoning across agents with independent context windows, the system effectively expands the total computational budget available for any given task. The team also notes that upgrading from Claude Sonnet 3.7 to Claude Sonnet 4 yields a larger performance gain than simply doubling the token budget on the older model, underscoring how model quality acts as an efficiency multiplier on raw token expenditure.
The candor about trade-offs is notable. Anthropic acknowledges that agents consume approximately four times more tokens than standard chat interactions, and multi-agent systems consume roughly fifteen times more. This economic reality constrains where the architecture is viable: it is best suited to high-value tasks involving heavy parallelization, information volumes that exceed single context windows, and numerous complex tool integrations. The team explicitly cautions that most coding workflows — where subtasks are interdependent rather than parallel — are a poor fit for the current architecture, and that real-time inter-agent coordination remains an unsolved problem. This honest scoping of applicability is significant, as it signals that Anthropic views multi-agent deployment as domain-selective rather than universally applicable.
The broader context is that Anthropic's publication arrives during a period of intense industry-wide investment in agentic AI systems. Competitors including OpenAI, Google DeepMind, and a range of startups are pursuing similar orchestrator-worker and multi-agent topologies, and the race to establish reliable, production-grade agentic pipelines has become a central axis of competition in frontier AI. Anthropic's decision to publish its architectural reasoning and quantitative performance data publicly — rather than keeping it as proprietary infrastructure knowledge — reflects a strategy of positioning Claude as a platform for third-party developers building their own agent systems, not merely an end-user product. The lessons shared around prompt engineering, tool design, and evaluation methodology are framed explicitly as transferable principles, suggesting Anthropic is actively cultivating an ecosystem of builders working atop its models.
The analogy Anthropic draws between multi-agent AI systems and human collective intelligence is more than rhetorical. It points to a structural thesis: that the performance ceiling of individually capable models is lower than the performance ceiling of coordinated networks of those models, and that architectural innovation in coordination may matter as much as raw model capability improvements. If token usage explains 80% of performance variance on hard research tasks, then the primary constraint on agentic system quality is not model intelligence per se, but the systems engineering that determines how efficiently and extensively those models are deployed. This reframes the competitive landscape: the frontier of AI capability is increasingly determined not only by what a single model knows or can reason through, but by how intelligently that model's compute is orchestrated at scale.


 Read original article →
Read original article →