Detailed Analysis
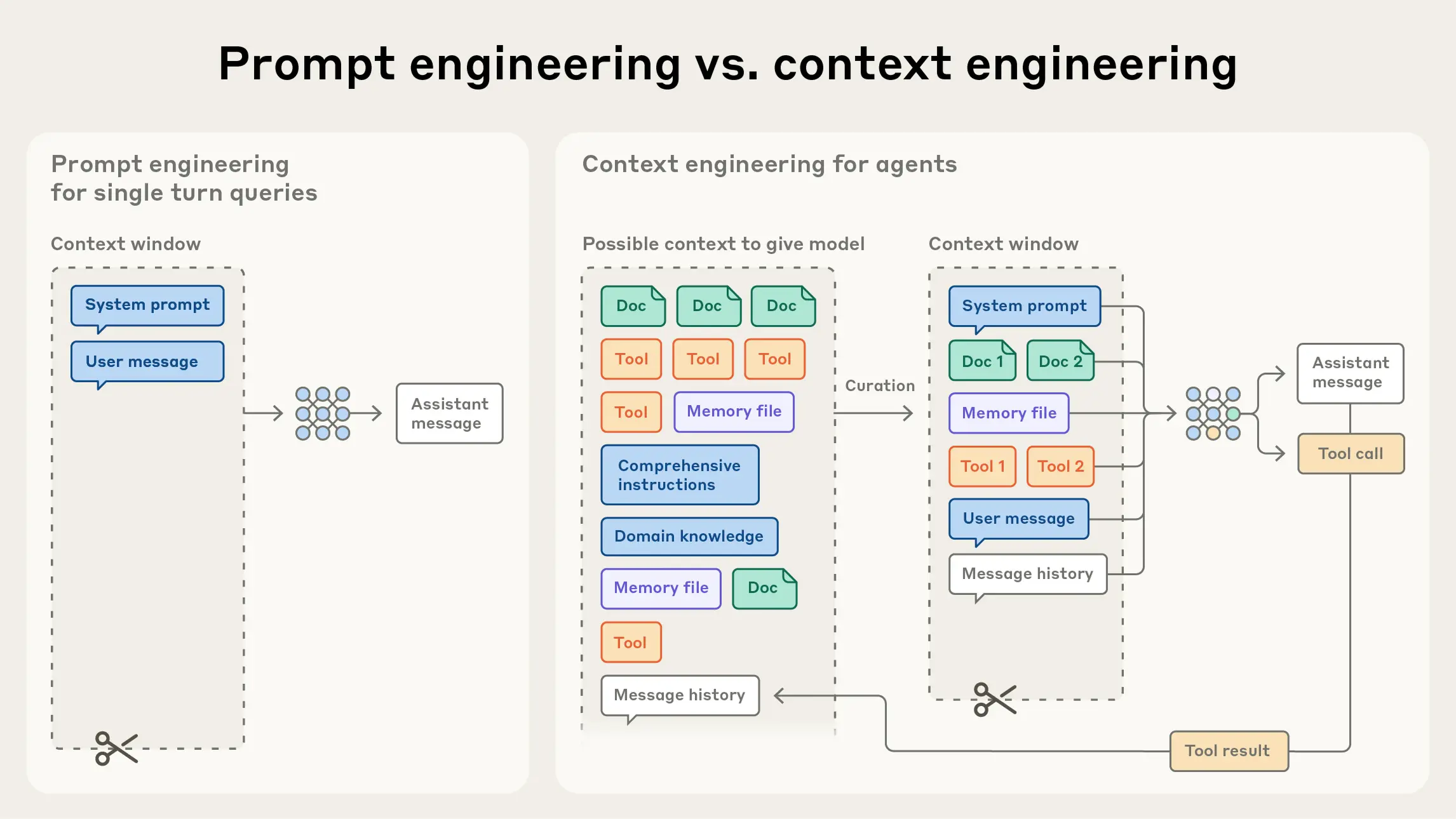
Context engineering has emerged as the next evolutionary stage beyond prompt engineering in applied AI development, representing a fundamental shift in how practitioners conceptualize and manage interactions with large language models (LLMs). Where prompt engineering focused narrowly on the craft of writing effective instructions — particularly system prompts — context engineering addresses the broader challenge of curating and optimizing the entire set of tokens available to a model during inference. This includes system instructions, tool definitions, Model Context Protocol (MCP) integrations, external data sources, and multi-turn message histories. Anthropic, the company behind the Claude family of models, has published guidance framing context engineering as the natural successor to prompt engineering, driven by the increasing complexity of agentic AI systems that operate over extended time horizons and multiple inference cycles rather than single-shot tasks.
The technical case for context engineering rests on a well-documented phenomenon called context rot, wherein a model's ability to accurately recall and reason over information degrades as the number of tokens in its context window grows. This degradation stems from the transformer architecture underlying all major LLMs, in which every token attends to every other token, producing n² pairwise relationships as sequence length increases. This exponential scaling creates a finite "attention budget" that becomes progressively strained with larger contexts. Compounding this architectural constraint is a distributional one: models are trained predominantly on shorter sequences, meaning they have fewer specialized parameters and less optimization for managing long-range dependencies. The result is not a hard performance cliff but a gradient of diminishing returns — models remain capable at longer contexts but exhibit measurable reductions in retrieval precision and complex reasoning relative to their performance on shorter, denser inputs.
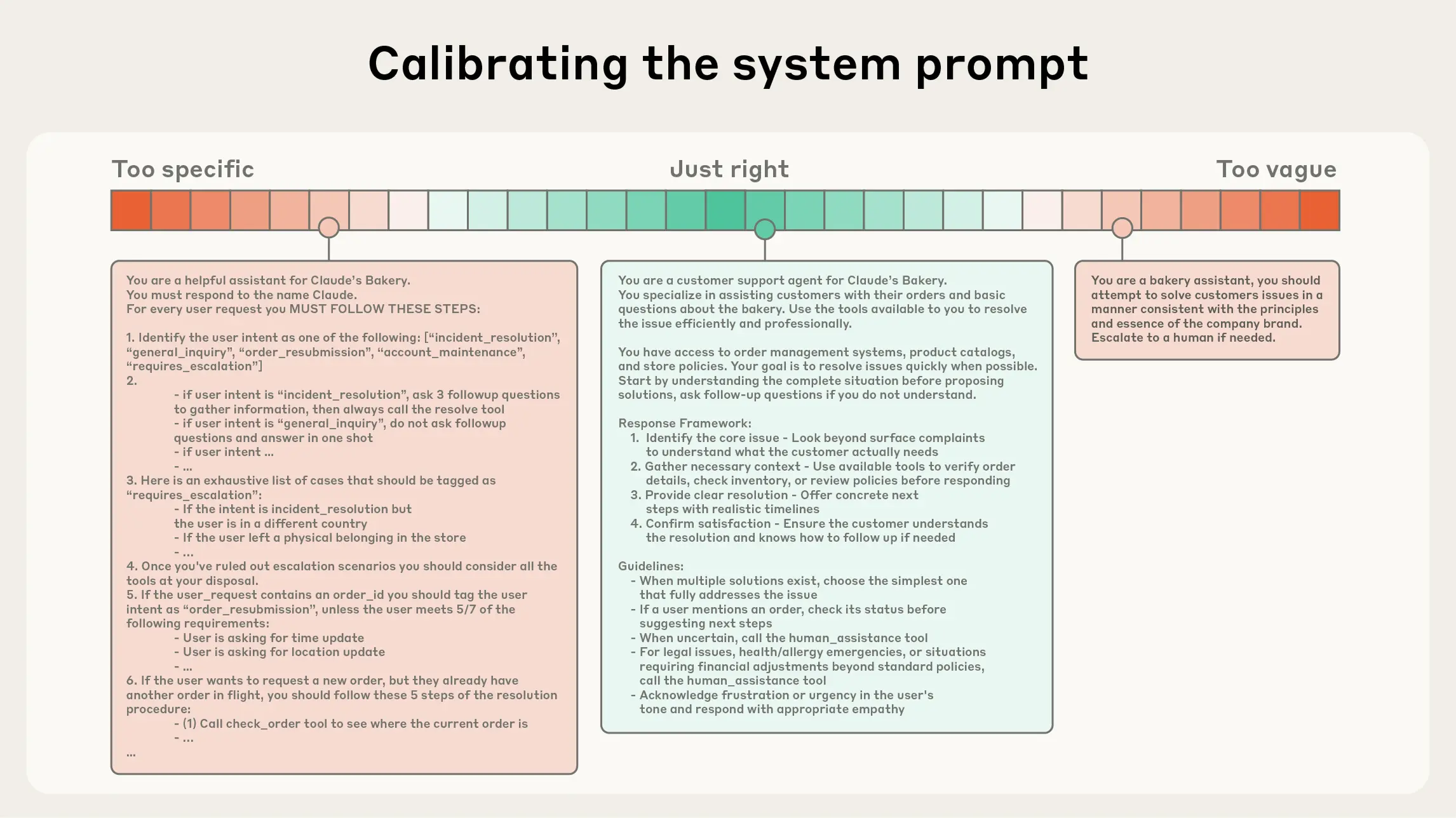
Anthropic's guidance emphasizes that effective context engineering requires treating context as a scarce resource, with the governing principle being to identify the smallest possible set of high-signal tokens that maximize the probability of a desired outcome. In practice, this translates into discipline around system prompt design, which should occupy a "Goldilocks zone" of specificity — concrete enough to guide model behavior without hardcoding brittle logic, yet flexible enough to avoid over-constraining the model. The article identifies two common failure modes at either extreme: engineers who embed overly rigid, procedural instructions that create maintenance complexity and fragility, and engineers who provide vague, high-level guidance that falsely assumes shared context and fails to give the model actionable signals. Striking the right balance requires iterative refinement rather than the one-time authorship characteristic of classic prompt engineering, as context must be re-curated at each inference step.
This development carries significant implications for the broader trajectory of AI system design. As agents grow more capable and are deployed in longer-horizon, multi-step workflows — autonomously browsing the web, executing code, calling APIs, or coordinating with other agents — the volume of potentially relevant information generated per session grows rapidly. Without deliberate strategies to filter, compress, and prioritize that information before it enters the context window, performance degrades in ways that are difficult to attribute to model capability alone. Context engineering thus becomes a key differentiator in the quality and reliability of production AI systems, shifting a meaningful portion of AI engineering work from the linguistic domain of instruction writing into the architectural domain of information management and pipeline design.
The broader trend reflected in Anthropic's framing is the maturation of applied AI from a practice centered on model prompting toward one resembling traditional software engineering, complete with considerations around state management, resource constraints, and system reliability. Just as early web development focused heavily on content before evolving to emphasize infrastructure, caching, and data pipelines, AI application development is moving toward an era where context architecture — what information is stored, retrieved, compressed, and presented to the model at each decision point — may prove as consequential as model selection or prompt quality. For organizations building on LLMs, this signals a need to invest in systematic approaches to context design and to develop tooling that makes the ongoing curation of agentic context both observable and controllable.

 Read original article →
Read original article →