Detailed Analysis
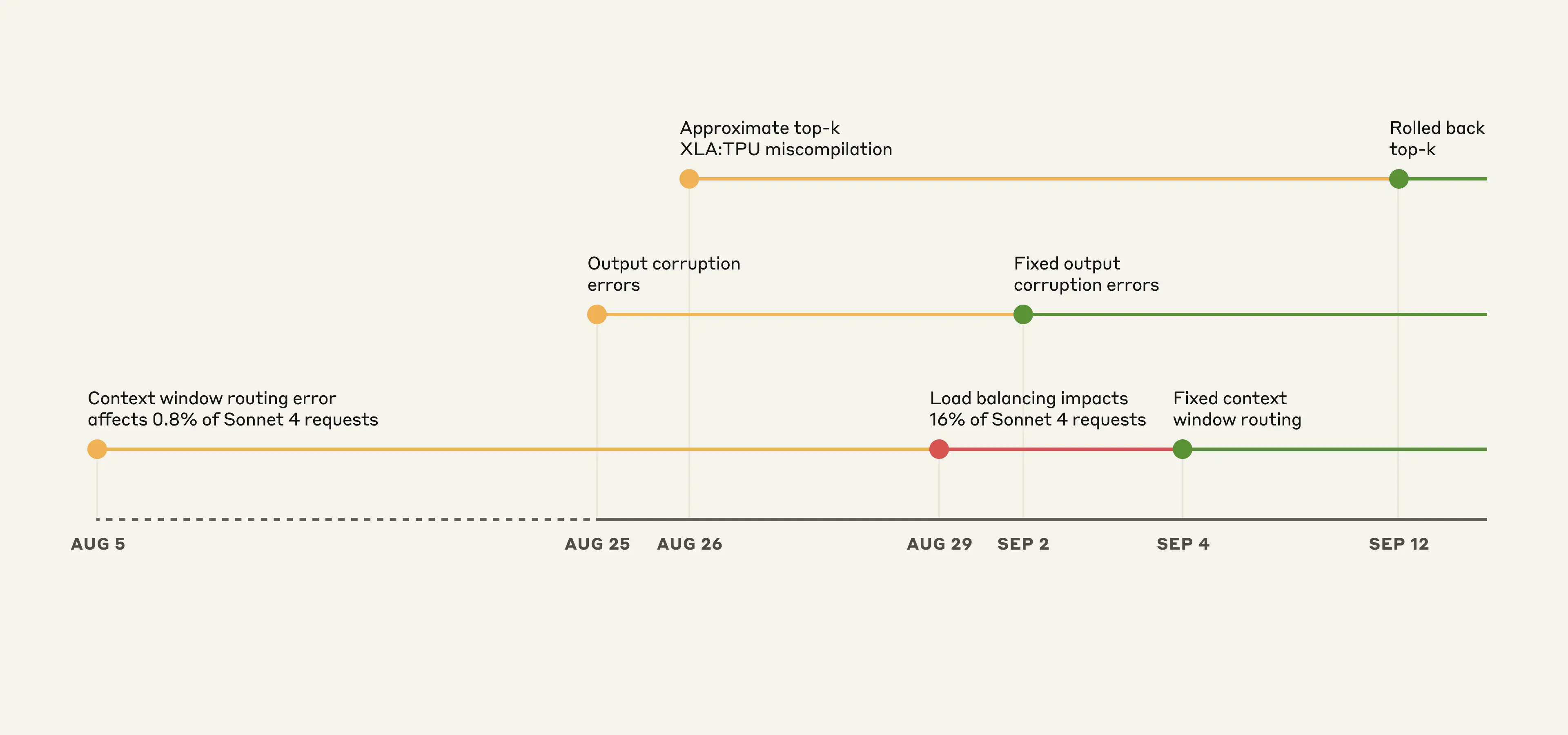
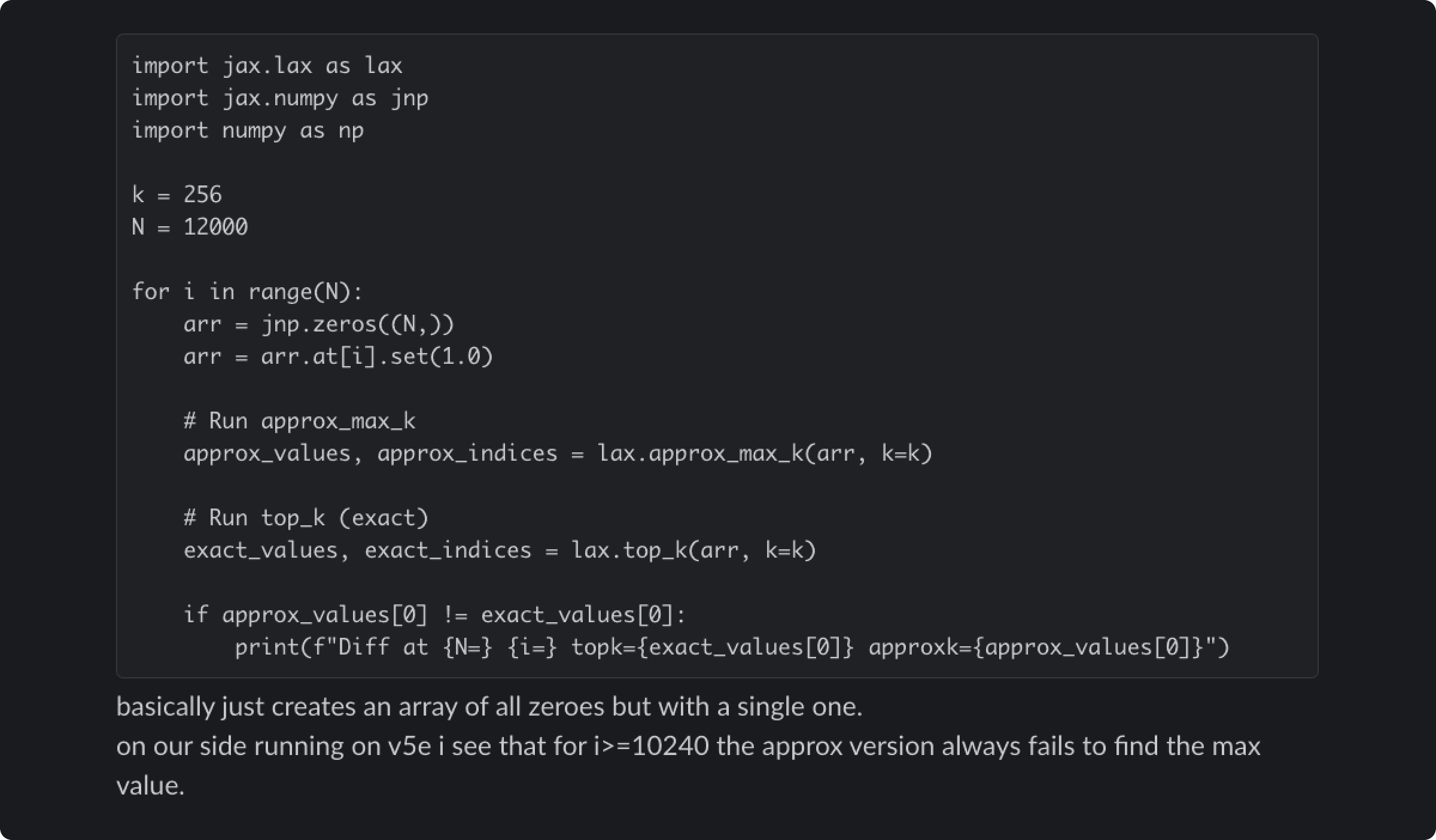
Anthropic publicly disclosed a postmortem in late 2025 detailing three overlapping infrastructure bugs that intermittently degraded Claude's response quality between early August and mid-September. The issues affected multiple Claude model versions — including Sonnet 4, Opus 4.1, Opus 4, Haiku 3.5, and Opus 3 — across Anthropic's first-party API, with limited impact on Amazon Bedrock and Google Cloud's Vertex AI. The first bug, introduced August 5, misrouted short-context requests to servers configured for an unreleased 1M token context window, eventually affecting up to 16% of Sonnet 4 requests at peak impact on August 31 after a load balancing change amplified the problem. The second bug, deployed August 25, stemmed from a TPU server misconfiguration that corrupted token generation, producing anomalous characters such as Thai or Chinese script in response to English-language prompts. The third bug, also introduced August 25, triggered a latent miscompilation error in the XLA:TPU compiler through a change intended to improve token selection, affecting Haiku 3.5, and potentially Sonnet 4 and Opus 3 as well.
The disclosure is notable for its candor and technical specificity. Anthropic explicitly addressed user speculation that response quality might be intentionally throttled during periods of high demand, stating plainly that model quality is never reduced based on server load, time of day, or demand volume. This kind of direct rebuttal of user suspicion is relatively unusual in the industry and reflects the degree to which trust in AI system consistency has become a concrete commercial and reputational concern. The bugs went undetected for weeks in part because early user reports were difficult to distinguish from normal variation in feedback, and because the overlapping and intermittent nature of the three issues created contradictory signals — some users experienced severe degradation while others on the same platform saw no issues at all.
The technical complexity underlying the incident illuminates the operational challenges inherent in serving large language models at scale across heterogeneous hardware. Anthropic deploys Claude across AWS Trainium, NVIDIA GPUs, and Google TPUs, each requiring platform-specific optimizations while being held to strict equivalence standards so that users receive consistent output regardless of which hardware serves their request. The XLA:TPU compiler bug in particular — a latent flaw in a compiler used to optimize tensor computations — highlights that model quality is not solely a function of model weights or training, but is also deeply sensitive to low-level infrastructure decisions about compilers, routing logic, and runtime performance tuning. A single optimization change at the infrastructure layer can surface latent bugs with significant downstream effects on model behavior.
The incident also underscores the difficulties of monitoring for quality degradation in generative AI systems, where output quality is inherently subjective and highly variable. Unlike traditional software failures that produce clear error codes or service outages, degraded language model outputs can appear subtly wrong — less coherent, less accurate, or stylistically off — in ways that are easy to attribute to normal model variability. Anthropic's acknowledgment that user reports took weeks to prompt a formal investigation suggests that the tooling and processes for detecting quality regressions in production LLM systems remain immature across the industry. The company's stated remediation steps — including new detection tests for unexpected character outputs and collaboration with the XLA:TPU team on a compiler fix — represent incremental improvements to an infrastructure reliability discipline that is still being actively developed.
Anthropic's decision to publish this postmortem with a level of technical detail it does not typically share publicly reflects a broader industry tension between transparency and competitive sensitivity. For a company whose commercial positioning depends heavily on Claude being perceived as a reliable, high-quality assistant for enterprise and developer use cases, the reputational cost of unexplained quality degradation likely outweighed the cost of disclosure. The postmortem also serves a signaling function: by articulating the root causes, the affected populations, and the corrective measures taken, Anthropic positions itself as an organization capable of rigorous infrastructure accountability — a quality that matters increasingly as AI systems are embedded into critical workflows and the consequences of silent model degradation grow more significant.



 Read original article →
Read original article →