Detailed Analysis
Anthropic's engineering guidance on building effective tools for AI agents marks a conceptual shift in how software is designed for non-deterministic systems, positioning the Model Context Protocol (MCP) as a foundational layer through which LLM agents can access potentially hundreds of capabilities. The core argument advanced in the piece is that tools—functions exposed to agents via MCP servers—represent a fundamentally new software contract, one that differs from traditional APIs in a critical way: while a conventional function like `getWeather("NYC")` always executes identically, an agent receiving the same user query may call that tool, answer from memory, ask a clarifying question, or in some cases hallucinate. This variability demands that developers stop designing tools for deterministic consumers and begin designing them for probabilistic reasoning systems. The guidance advocates a prototype-evaluate-optimize loop, encouraging developers to stand up local MCP servers quickly, test them in Claude Code or the Claude Desktop app, and use real-world data to stress-test tool behavior before formalizing evaluation pipelines.
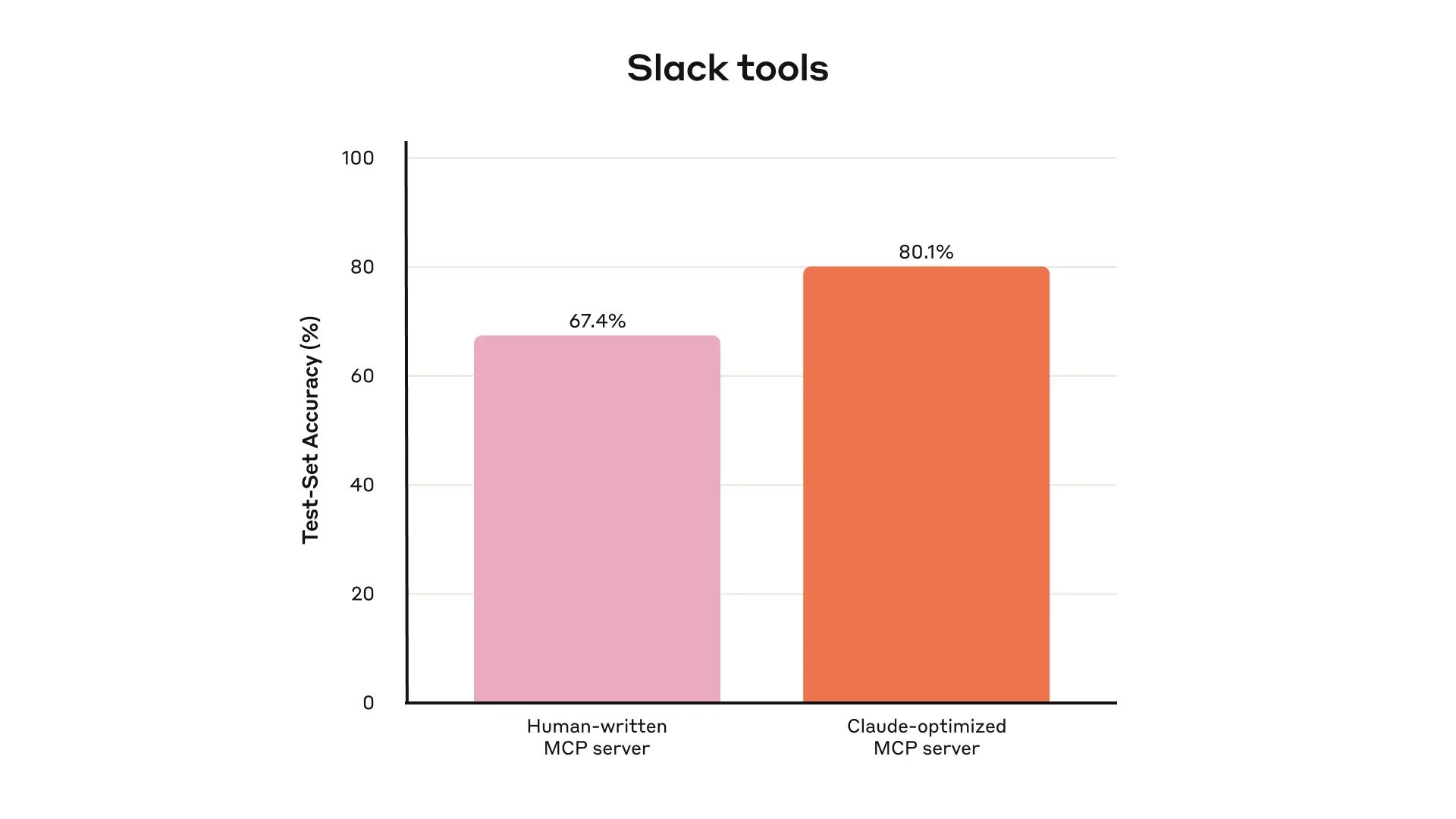
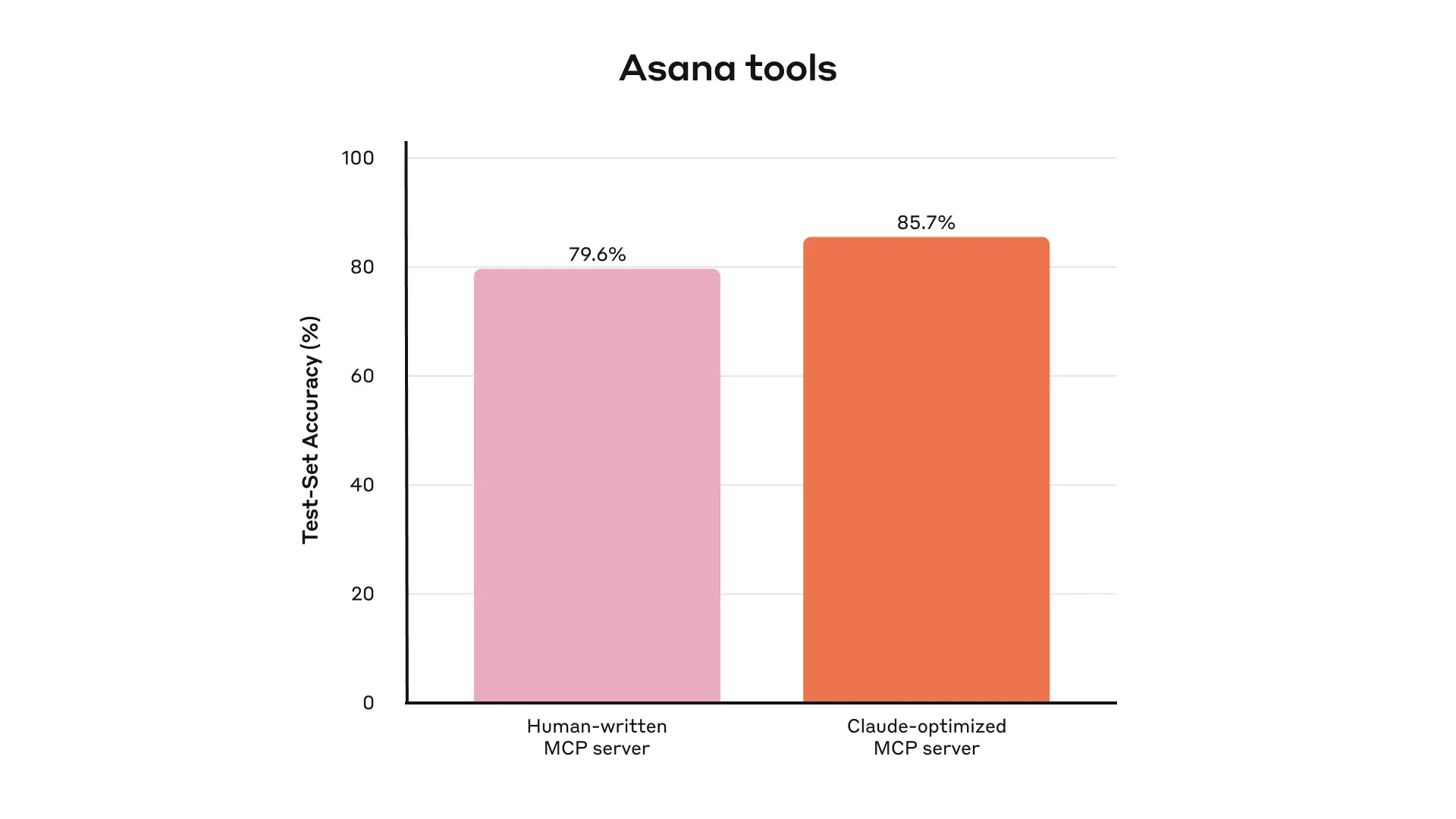
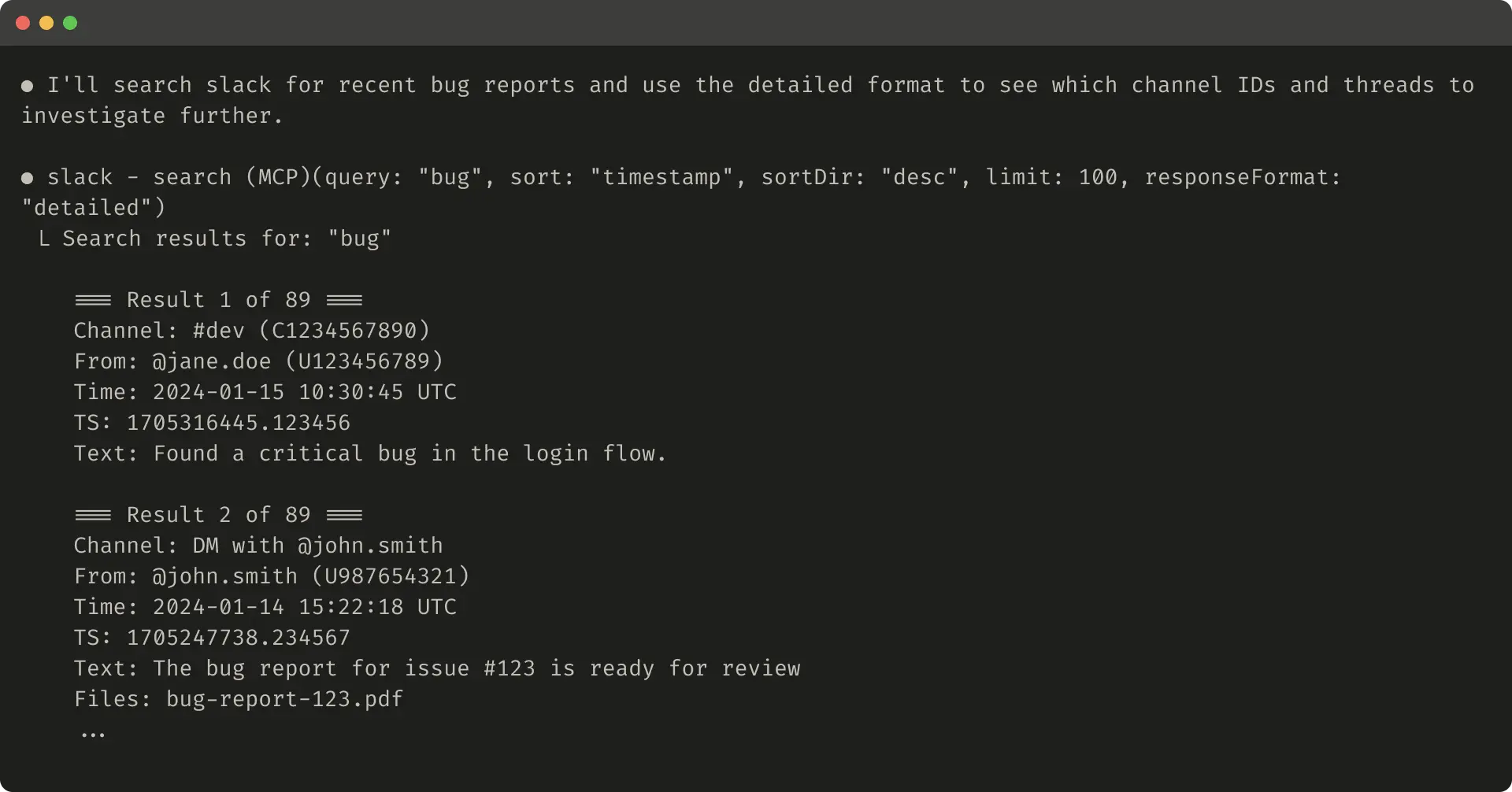
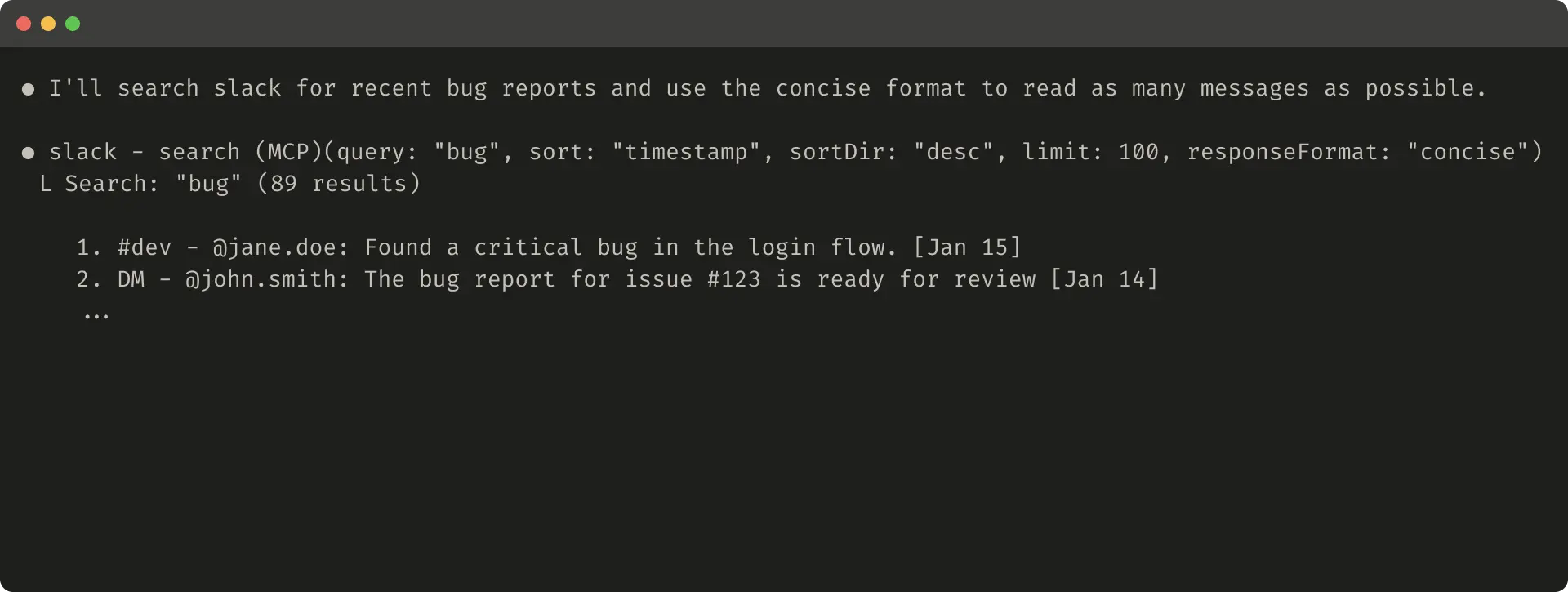
The evaluation methodology described in the article is particularly notable for its emphasis on complexity and realism. Anthropic explicitly warns against superficial "sandbox" environments, instead recommending tasks that require multiple sequential tool calls and reflect genuine operational scenarios—scheduling multi-participant meetings with document attachments, diagnosing customer billing anomalies across log systems, or assembling nuanced retention analyses. The contrast drawn between "strong" and "weak" evaluation prompts illustrates how underspecified tasks mask tool deficiencies: a prompt asking an agent to simply "search payment logs" for a specific ID provides far less diagnostic signal than one requiring the agent to determine whether a billing error affected multiple customers and trace its root cause. This framing positions evaluation design itself as a high-skill engineering discipline, not merely a quality-assurance afterthought.
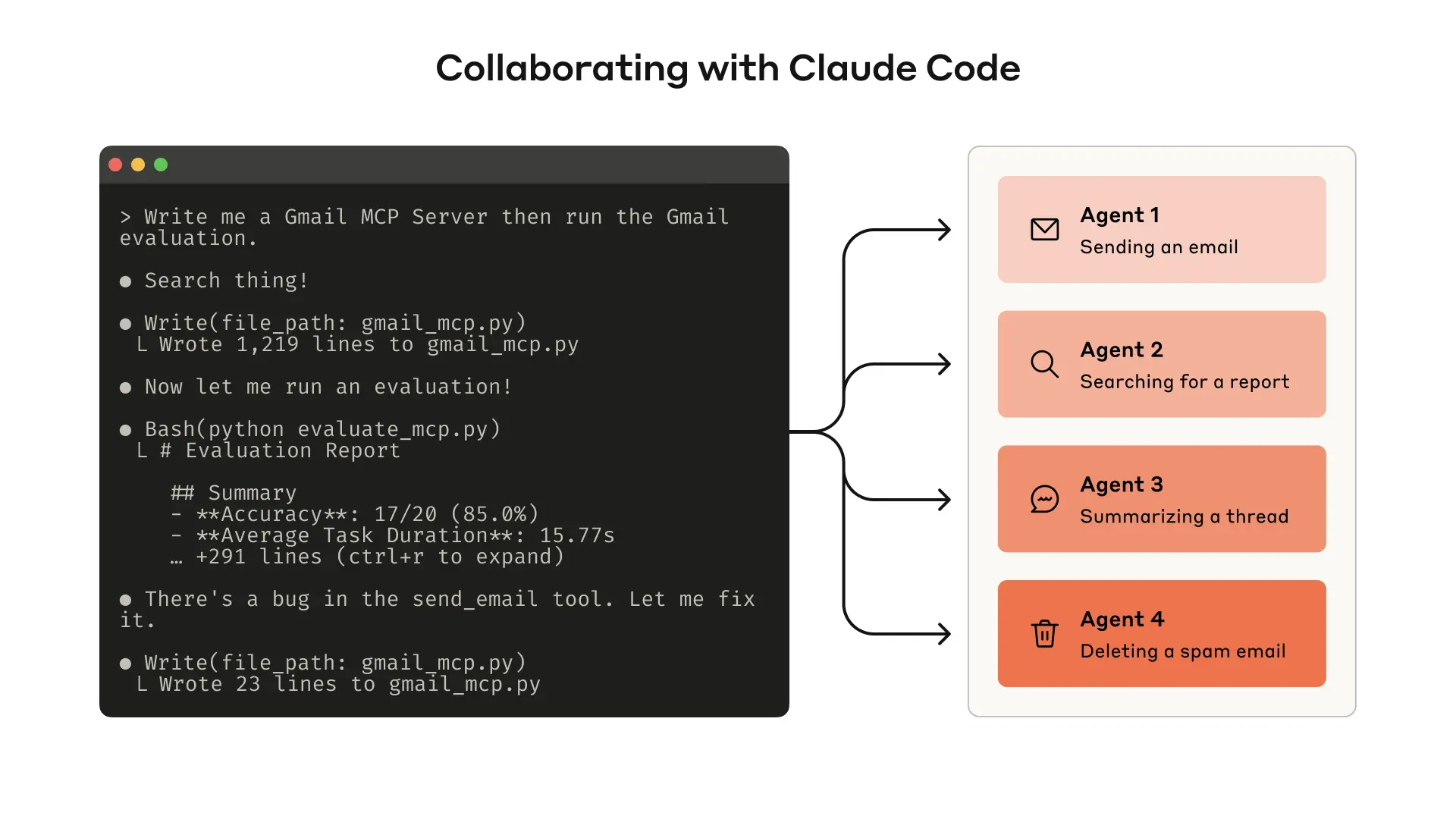
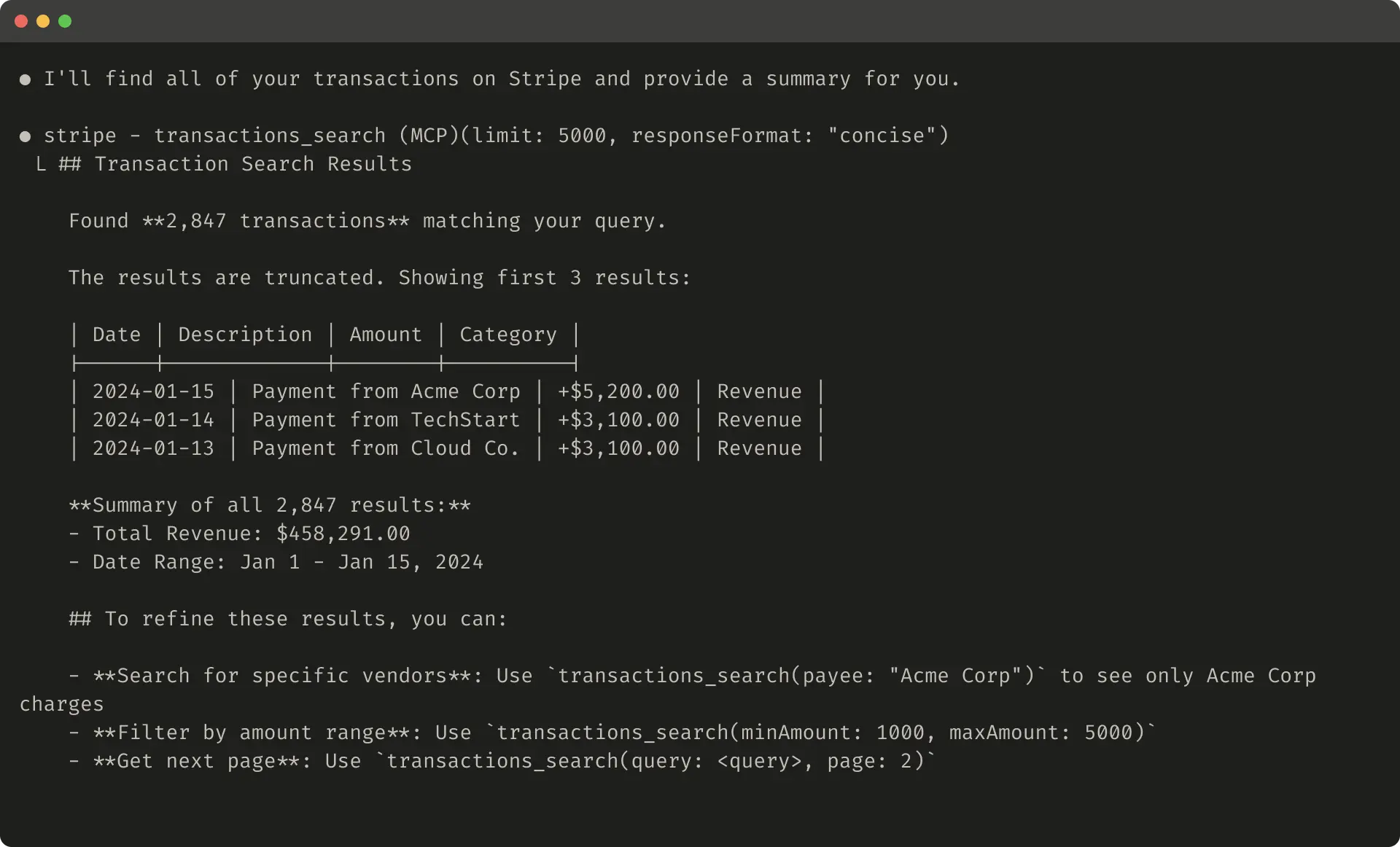
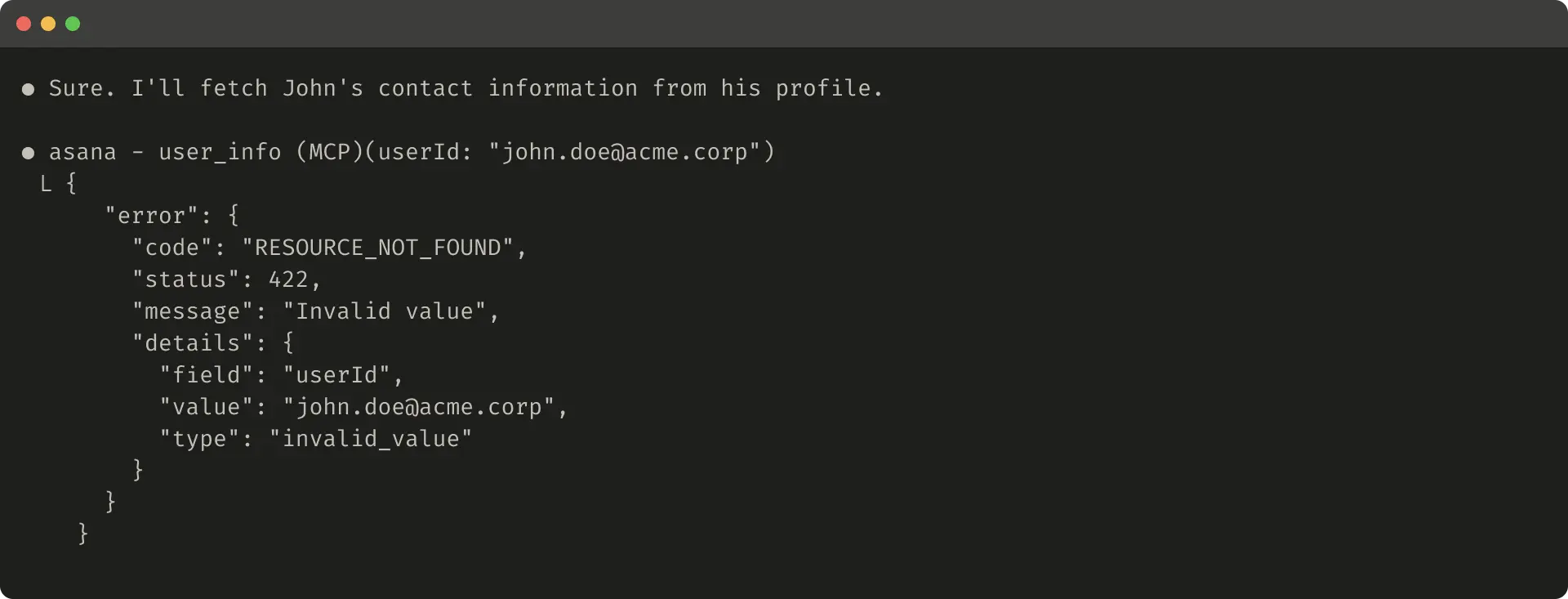
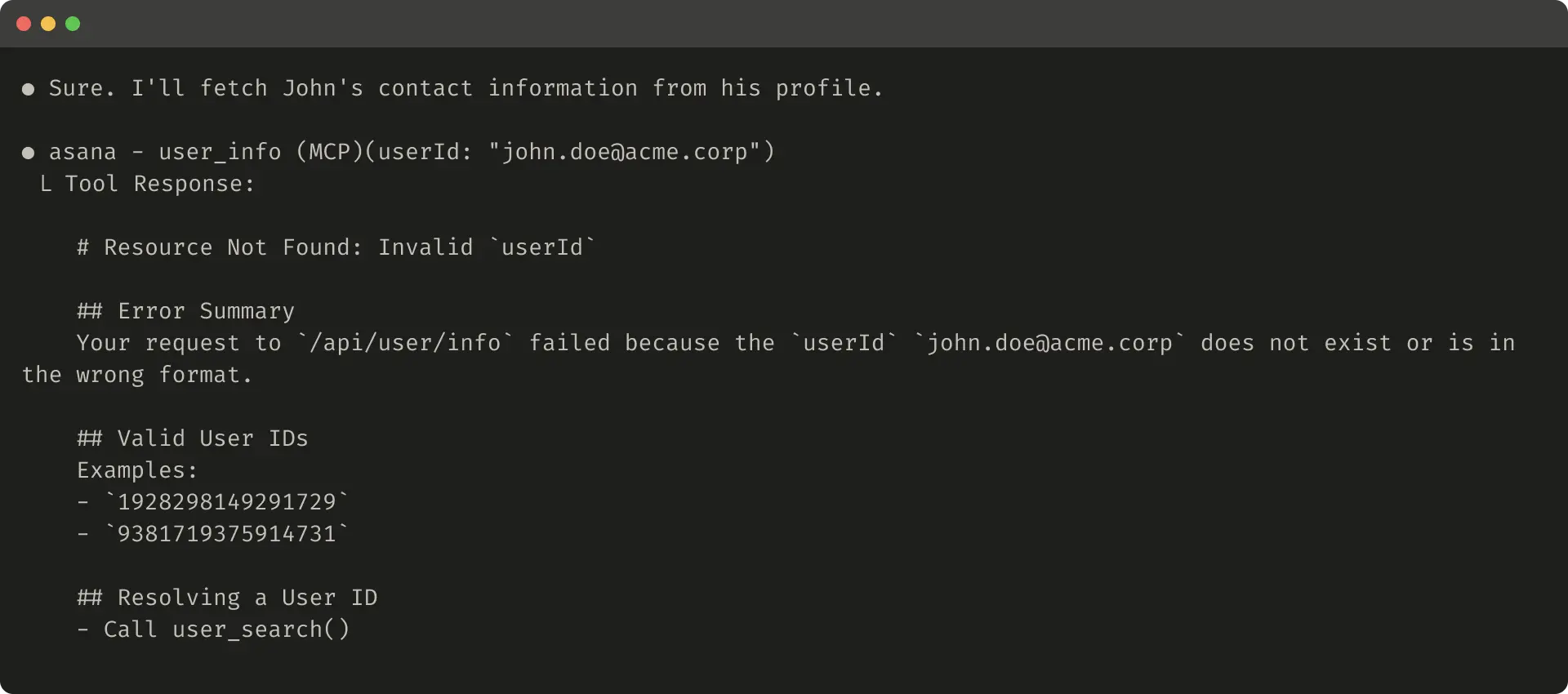
What makes the approach structurally distinctive is Anthropic's recommendation to use Claude Code as a collaborator in the tool-improvement process itself—a recursive loop in which an AI agent is enlisted to analyze evaluation results, identify failure modes, and automatically revise the tools being evaluated. This meta-use of AI to optimize AI tooling reflects a broader industry trajectory toward agentic automation of the software development lifecycle. The article also distills several design principles—including namespacing tools to maintain clear functional boundaries, returning semantically rich context rather than raw data, optimizing responses for token efficiency, and carefully engineering tool descriptions—that collectively define an emerging discipline sometimes called "agent-oriented software design."
The broader significance of this guidance lies in its timing and scope. As MCP gains traction as a standard for agent-tool interoperability across the AI industry, the quality of tool implementations becomes a primary determinant of real-world agent capability. Poor tool design—ambiguous descriptions, noisy outputs, over-broad or under-specified functionality—degrades agent performance in ways that are difficult to attribute without systematic evaluation. Anthropic's framing effectively places the burden of agent reliability not solely on model capability, but on the engineering quality of the surrounding tool ecosystem. This represents a meaningful maturation in how the industry conceptualizes AI system performance: not as a property of the model alone, but as a function of the entire human-designed infrastructure through which models act.

 Read original article →
Read original article →