Detailed Analysis
Anthropic's introduction of the "think" tool represents a deliberate architectural intervention in how Claude handles complex, multi-step reasoning tasks during agentic tool use. Unlike extended thinking — which operates as a pre-response deliberation phase before Claude begins generating output — the "think" tool inserts a structured reasoning checkpoint mid-response, allowing Claude to pause, assess newly acquired information from tool call results, and determine whether it has sufficient context to proceed. The tool itself is technically minimal: a simple JSON-specified function that accepts a string "thought" parameter and appends it to the processing log without querying external systems or modifying any database. This simplicity belies its practical impact, as Anthropic's benchmarking demonstrates substantial performance gains across realistic agentic scenarios.
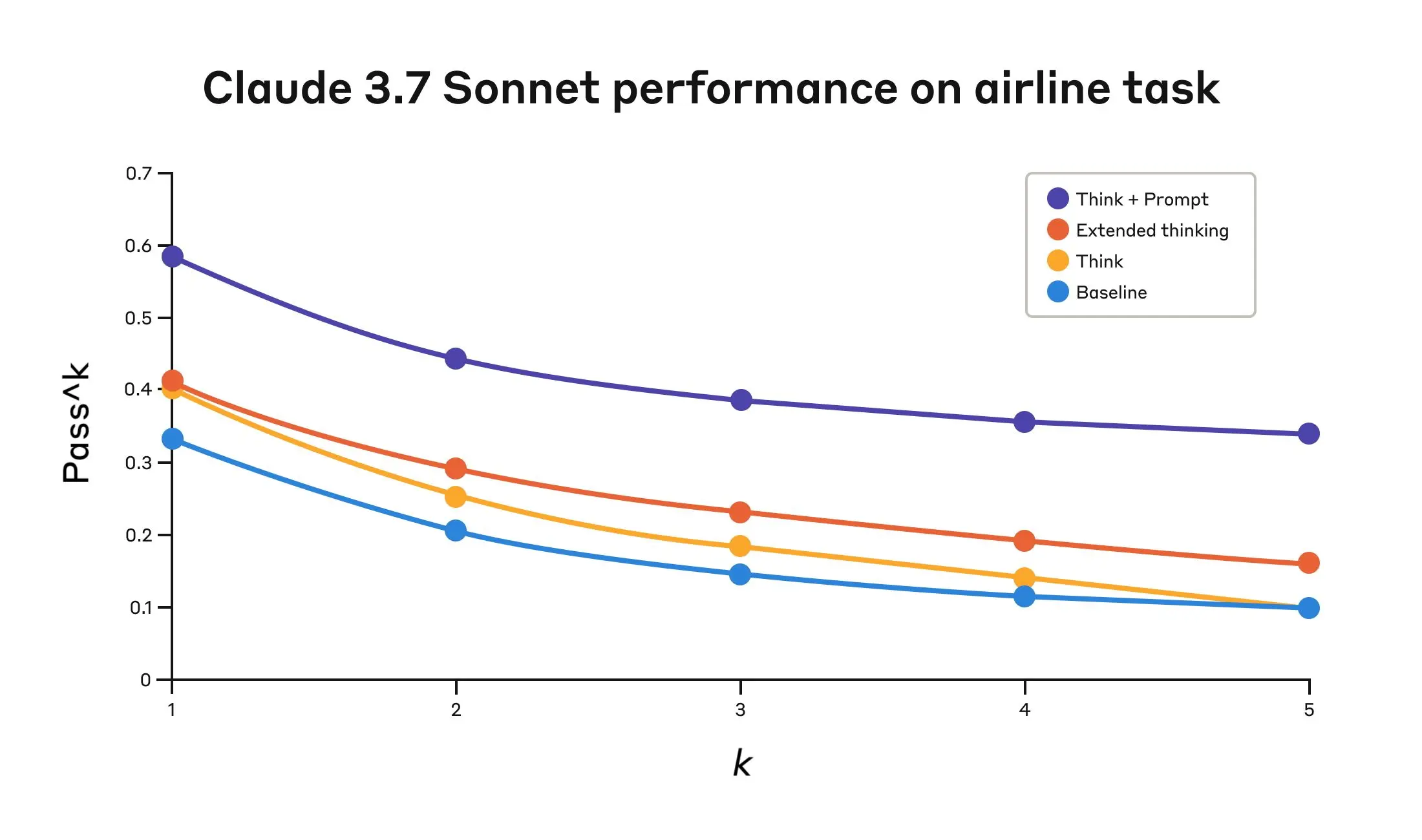
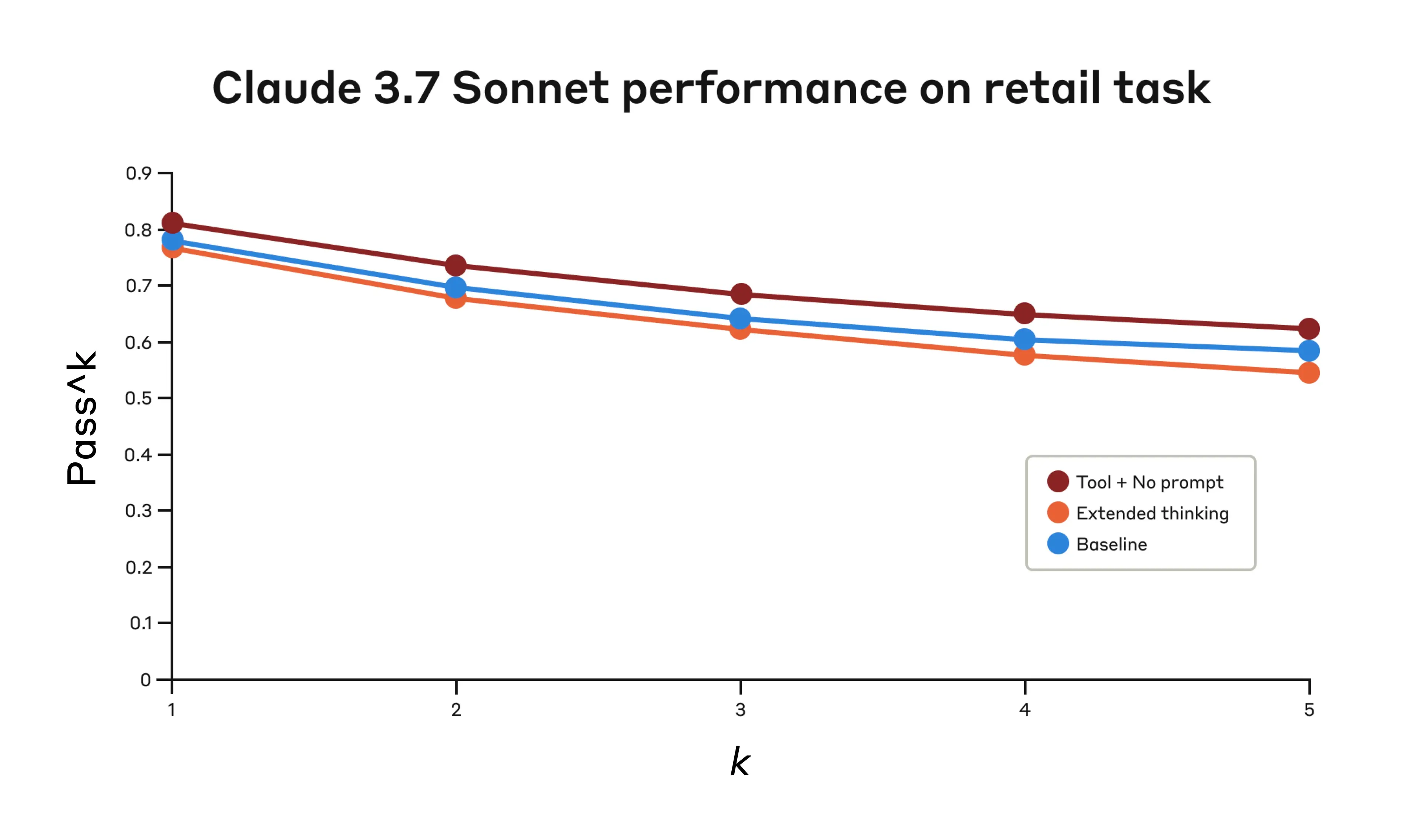
The performance results, drawn from τ-bench — a benchmark designed to simulate complex customer service environments requiring consistent policy adherence and sequential tool use — show the "think" tool delivering significant improvements over baseline configurations. In the airline domain, pairing the tool with an optimized prompt lifted pass^1 scores from 0.332 to 0.584, a relative improvement exceeding 75% at the k=1 level, while the retail domain saw scores move from 0.783 to 0.812. Critically, the evaluation metric used, pass^k, measures whether all k independent trials of a task succeed — a much stricter standard than the common pass@k metric, which only requires one success among k attempts. This framing is particularly meaningful for enterprise deployment contexts, where inconsistency in policy-following or sequential decision-making carries real operational risk. The optimized prompt paired with the think tool instructs Claude to explicitly enumerate applicable rules and reason through their relevance before acting, a technique that meaningfully boosts consistency scores across trial repetitions.
The distinction Anthropic draws between the "think" tool and extended thinking illuminates a broader design philosophy around separating different cognitive modes. Extended thinking is suited for scenarios where all necessary information is available upfront — mathematics, coding, physics problems, or simple tool call sequences — because its reasoning is deeper, more comprehensive, and completed before any response generation begins. The "think" tool, by contrast, is optimized for environments where Claude encounters new and potentially unexpected information mid-task, such as tool return values that require careful interpretation before proceeding. These are not competing approaches but complementary ones, with each occupying a distinct niche in the agentic reasoning stack. The December 2025 update appended to the article acknowledges this evolution, noting that extended thinking improvements have since made it the recommended default in most cases, suggesting that the "think" tool's primary relevance now centers on uniquely sequential, information-dependent workflows.
This development connects to a wider trend in the AI industry toward giving large language models more structured mechanisms for self-monitoring and error correction during task execution. Techniques like chain-of-thought prompting, scratchpad reasoning, and process-reward models all share the underlying premise that surfacing intermediate reasoning states improves both accuracy and reliability. The "think" tool operationalizes this principle at the infrastructure level rather than the prompt level alone, making structured mid-task reflection a discrete, inspectable tool call rather than an implicit capability. For developers building agentic systems on top of Claude, this creates an auditable reasoning trail — each invocation of the think tool produces a logged thought that can be reviewed, which has meaningful implications for debugging, compliance, and trust in high-stakes automated workflows. As agentic AI deployments mature and face greater scrutiny around accountability and consistency, this kind of transparent intermediate reasoning infrastructure is likely to become an increasingly standard component of production systems.

 Read original article →
Read original article →