Detailed Analysis
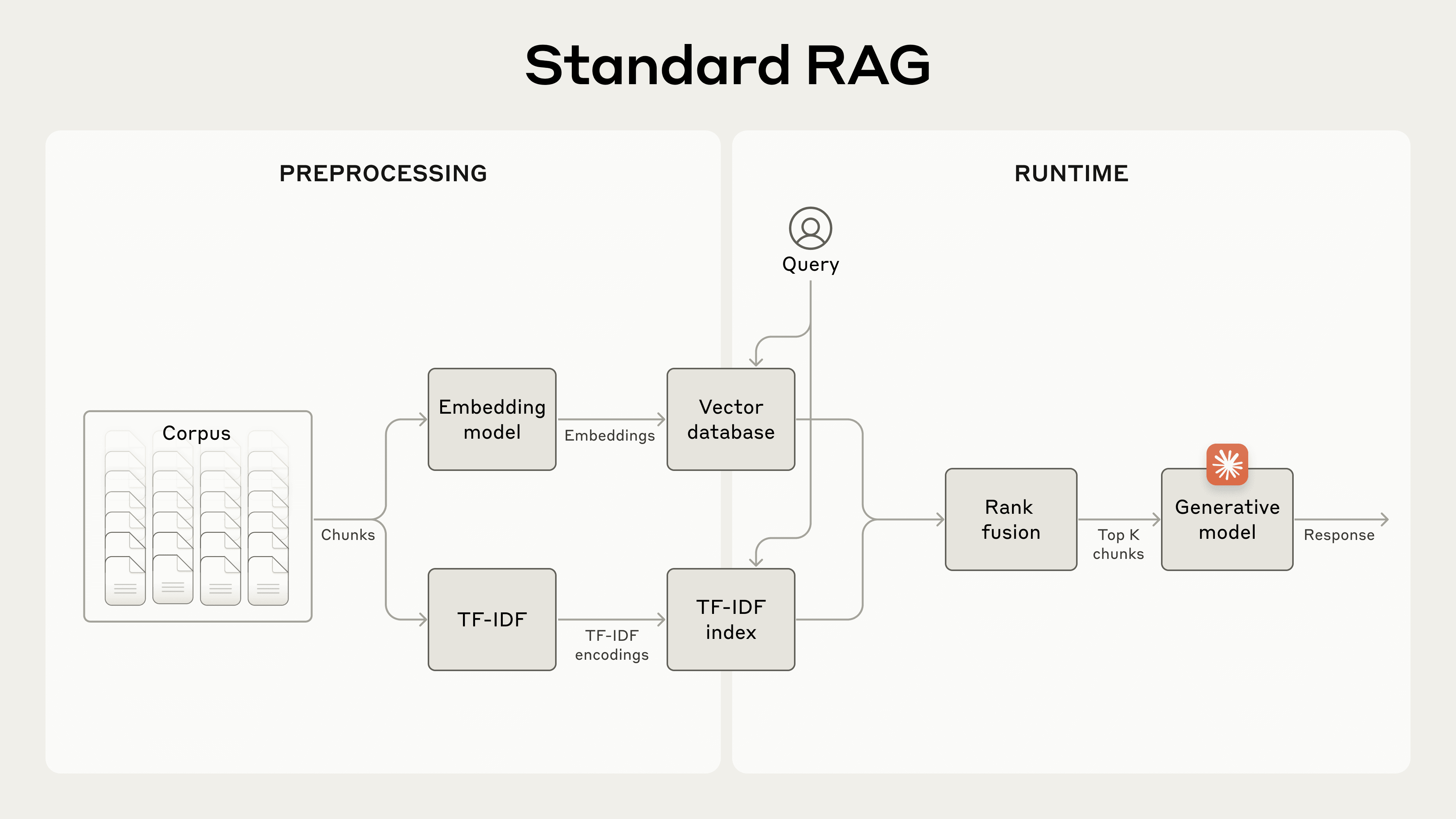
Anthropic has introduced Contextual Retrieval, a novel technique designed to significantly improve the accuracy of information retrieval in AI systems built on Retrieval-Augmented Generation (RAG). Traditional RAG systems, which are widely used to extend an AI model's knowledge beyond its training data, work by breaking large document collections into smaller chunks, converting them into vector embeddings, and retrieving the most relevant chunks at query time. While this approach scales effectively to large knowledge bases, it carries an inherent flaw: the chunking process strips away surrounding context, leaving individual text segments ambiguous or incomplete. A chunk stating "the company's revenue grew by 3% over the previous quarter," for instance, becomes nearly useless when divorced from identifying information about which company or time period is being referenced.
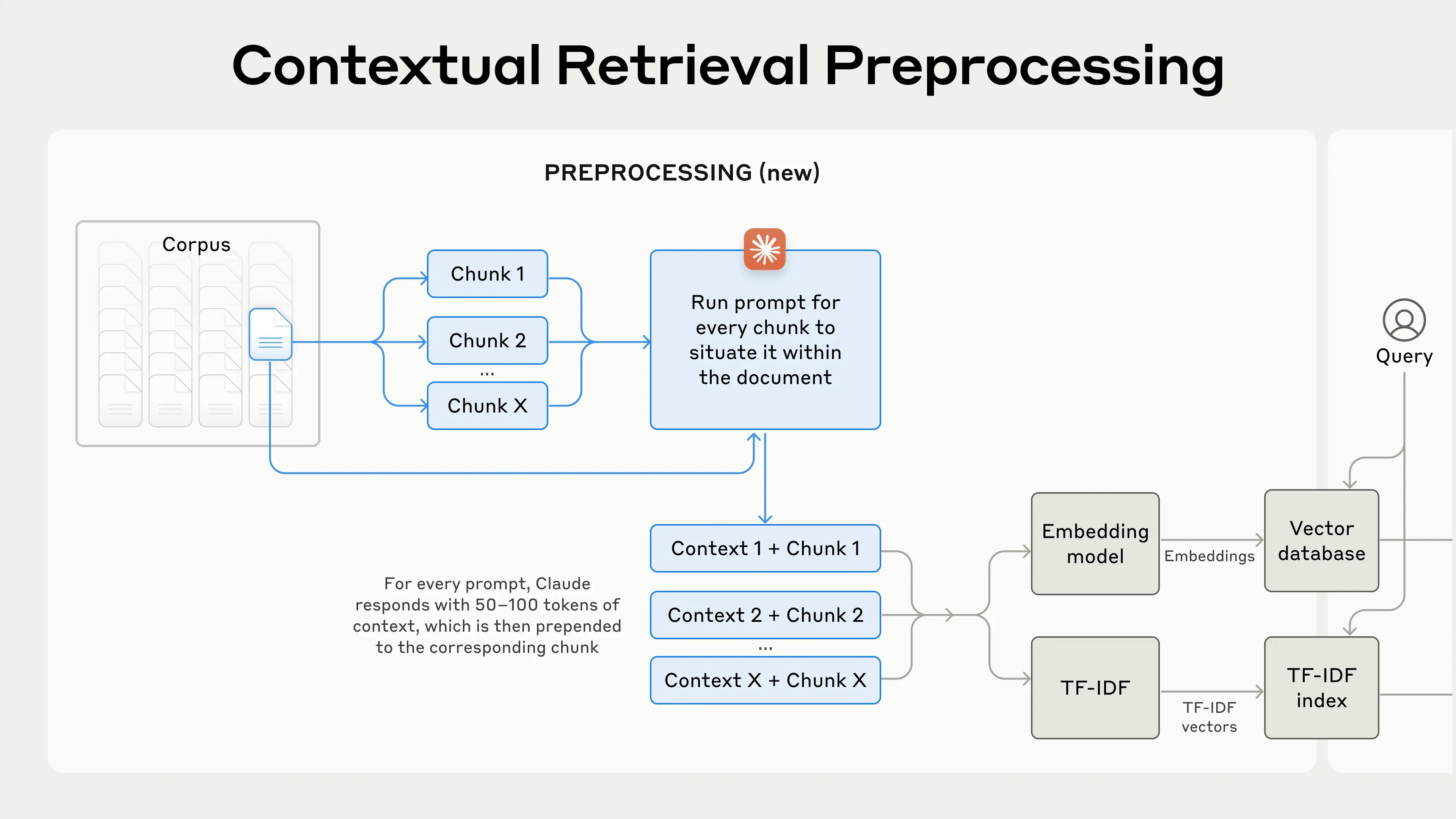
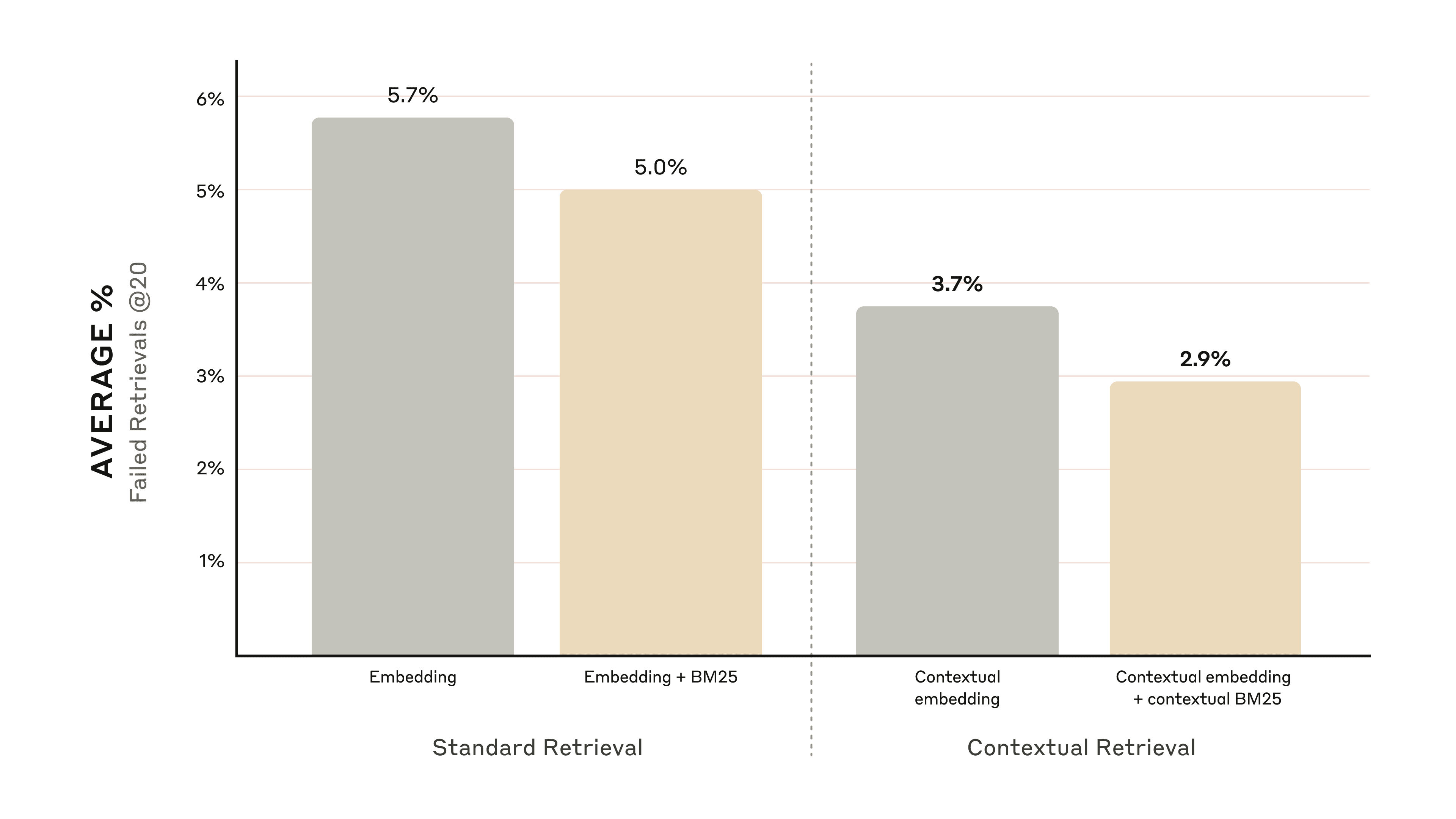
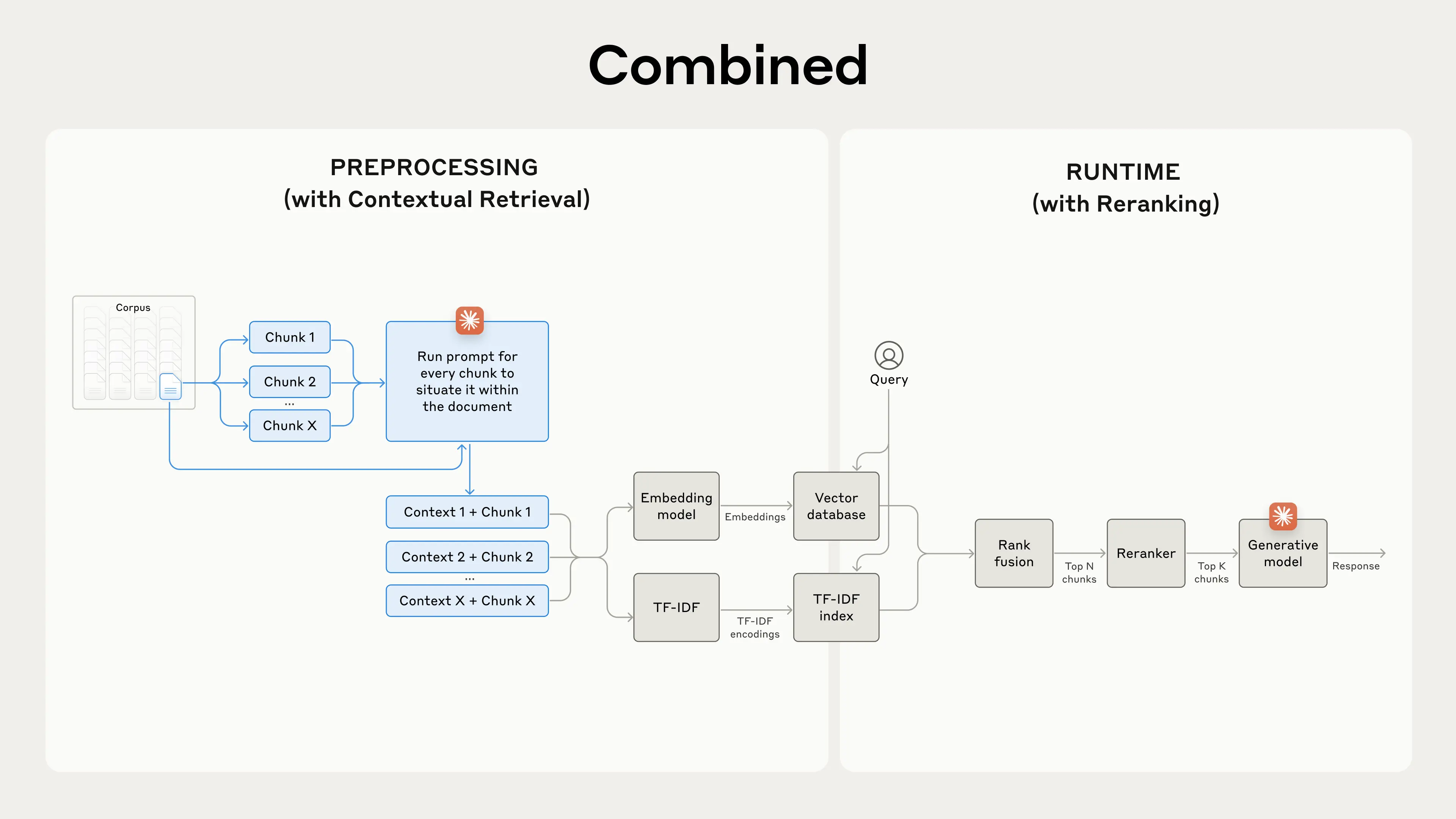
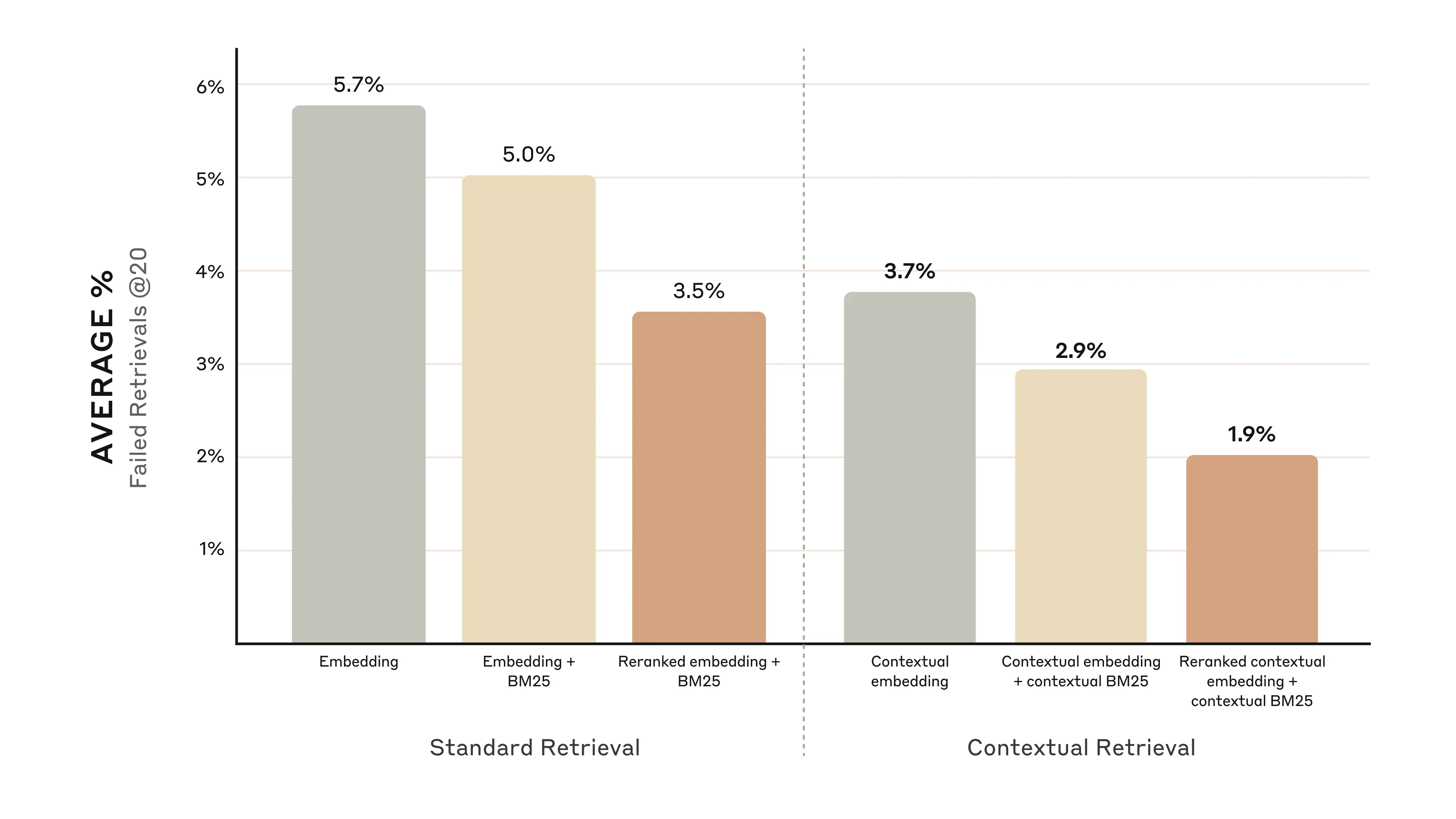
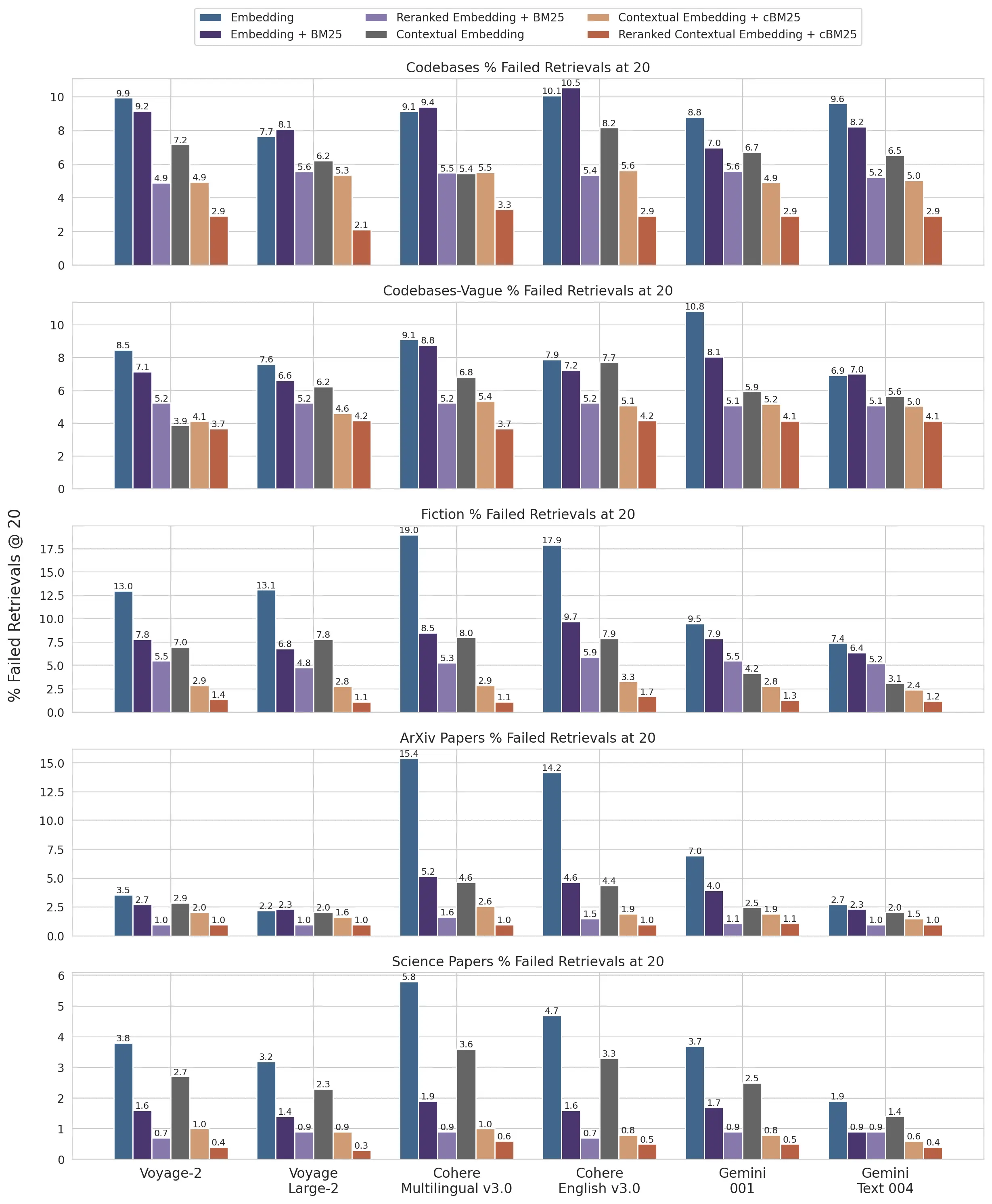
Contextual Retrieval addresses this limitation through two complementary sub-techniques: Contextual Embeddings and Contextual BM25. Rather than encoding chunks in isolation, the method prepends chunk-specific explanatory context to each segment before it is processed, preserving critical metadata and situational information that would otherwise be lost. This is paired with BM25 (Best Matching 25), a lexical ranking function that complements semantic embedding models by excelling at exact-match retrieval — particularly valuable for queries involving technical identifiers, product codes, or precise terminology that embedding models may generalize over. The combined approach reduces failed retrievals by 49% on its own, and by 67% when augmented with a reranking step, representing meaningful, measurable gains in downstream task performance.
The release also highlights a tiered strategy for knowledge base management that reflects a pragmatic engineering philosophy. For knowledge bases smaller than approximately 200,000 tokens — roughly 500 pages — Anthropic suggests that including the entire knowledge base directly in the prompt may be the simplest and most effective solution, particularly given the company's recently released prompt caching feature, which reduces latency by more than 2x and costs by up to 90% by allowing frequently used prompts to be cached between API calls. Contextual Retrieval is thus positioned as the appropriate tool specifically when knowledge bases grow large enough to exceed context window limits, ensuring developers have a clear, scalable path as their data needs expand.
This development fits within a broader industry trend of closing the gap between raw model capability and real-world deployment utility. A model's intelligence is only as actionable as its access to relevant, accurate information at inference time, and retrieval quality has long been one of the most significant bottlenecks in enterprise AI applications. By tackling the context destruction problem inherent in chunking — a limitation that has been recognized across the RAG research community — Anthropic is addressing a practical pain point that affects customer support systems, legal research tools, medical databases, and any domain requiring precise, large-scale knowledge retrieval. The provision of a ready-to-use cookbook further signals Anthropic's emphasis on developer accessibility, lowering the barrier for teams looking to deploy production-grade retrieval systems without building the underlying infrastructure from scratch.

 Read original article →
Read original article →