X
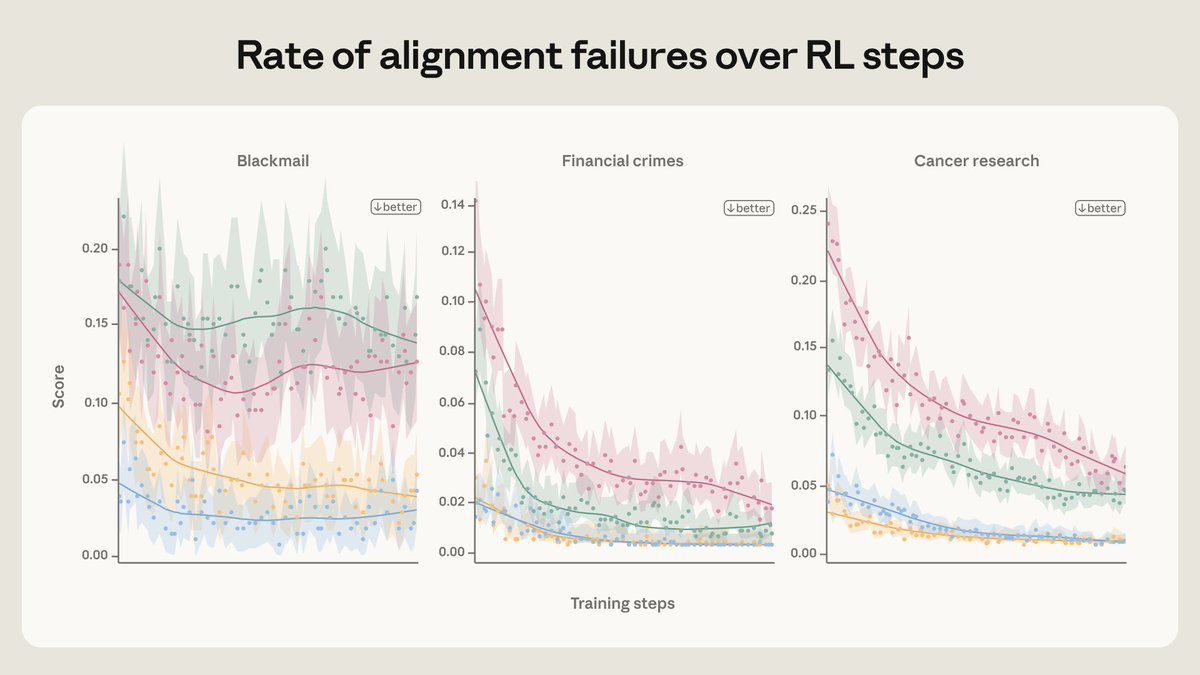
The improvements from these interventions survive reinforcement learning, and “s
X · AnthropicAI · 2026-05-08
Improvements from harmlessness interventions persist through reinforcement learning and stack additively with standard training methods. Fictional aligned-AI narrative examples reduced misalignment rates by 3x on unrelated evaluation scenarios, indicating that generalized reasoning about principled behavior generalizes better than rule-following. The core insight emphasizes understanding the "why" behind constraints rather than enumerating specific prohibited behaviors, as this reasoning approach generalizes to novel situations the model has not encountered during training.
Detailed Analysis
Anthropic's official Twitter account became the focal point of a fragmented but revealing public conversation about AI alignment research, user frustration, and the limits of large language model safety systems. The thread originates from an Anthropic announcement — truncated in its original form — stating that improvements derived from specific alignment interventions "survive reinforcement learning" and "stack" with the company's regular harmlessness training. Accompanying replies from technically engaged observers reference what appears to be a related finding: that training models on fictional narratives featuring aligned AI behavior reduced misalignment across unrelated evaluation scenarios by approximately threefold, even in situations the model had never previously encountered. These findings, if accurate, represent a meaningful advance in the understanding of how values generalize through large language models rather than requiring exhaustive case-by-case behavioral correction.
The substantive alignment commentary scattered throughout the thread highlights a key conceptual debate in AI safety research. Several replies argue that the traditional "whack-a-mole" approach to alignment — identifying and patching specific harmful behaviors — is fundamentally insufficient because the space of possible harmful edge cases is unbounded. The more durable intervention, according to this view, is instilling a model with robust reasoning about *why* certain behaviors are harmful, enabling generalization to novel situations. One commenter draws attention to the distinction between eliminating an undesirable behavior and understanding its origin, cautioning against conflating suppression with genuine alignment. These observations align with a broader shift in the field toward mechanistic interpretability and values-based training rather than purely behavioral suppression.
Running in parallel to this technical discourse is a stream of user grievances that illustrates the real-world friction generated by Anthropic's safety systems. One user reports losing four hours of collaborative research work — focused on organized crime in Israel and Iran — attributing the loss to Claude's safety filters triggering mid-session. The user's experience, whether the result of a genuine safety intervention or a technical failure, exemplifies a persistent tension in deploying safety-oriented AI systems: aggressive content filtering can appear indistinguishable from arbitrary censorship to end users, eroding trust and generating significant hostility. The thread was subsequently amplified by Grok, a competing AI assistant, which positioned itself as a contrast to Claude's perceived evasiveness — a form of competitive brand positioning that has become increasingly common as AI assistants compete for user loyalty.
The juxtaposition of Anthropic's alignment research announcements against this backdrop of user anger is instructive. The company is navigating a structural challenge: the same training philosophies designed to make Claude safer and more reliably aligned with human values are the source of user-facing behaviors that feel opaque, paternalistic, or unreliable. The claim that alignment improvements now "stack" and survive reinforcement learning is technically significant, but it does little to address the user experience problem when safety interventions occur without explanation or recovery mechanisms. The broader AI development landscape is grappling with this same tension, as every major lab faces pressure to demonstrate both safety rigor and practical usability — goals that remain difficult to fully reconcile at the product layer even as research-level alignment methods advance.

Don't Miss a Deploy
Claude moves fast. Get the signal — no noise — straight to your inbox every morning.