Detailed Analysis
Anthropic has released Claude Opus 4.8, an incremental but substantively improved upgrade to its flagship model tier, available at the same price as its predecessor Opus 4.7. The release arrives alongside several companion features: user-controllable effort levels on claude.ai, a "dynamic workflows" capability in Claude Code designed for large-scale problem-solving, and a fast mode that operates at 2.5 times standard speed while costing three times less than the equivalent fast mode on prior models. The model demonstrates benchmark improvements across coding, agentic tasks, reasoning, and knowledge work, with third-party testers citing gains in judgment quality, tool-calling efficiency, citation precision, and long-context coherence.
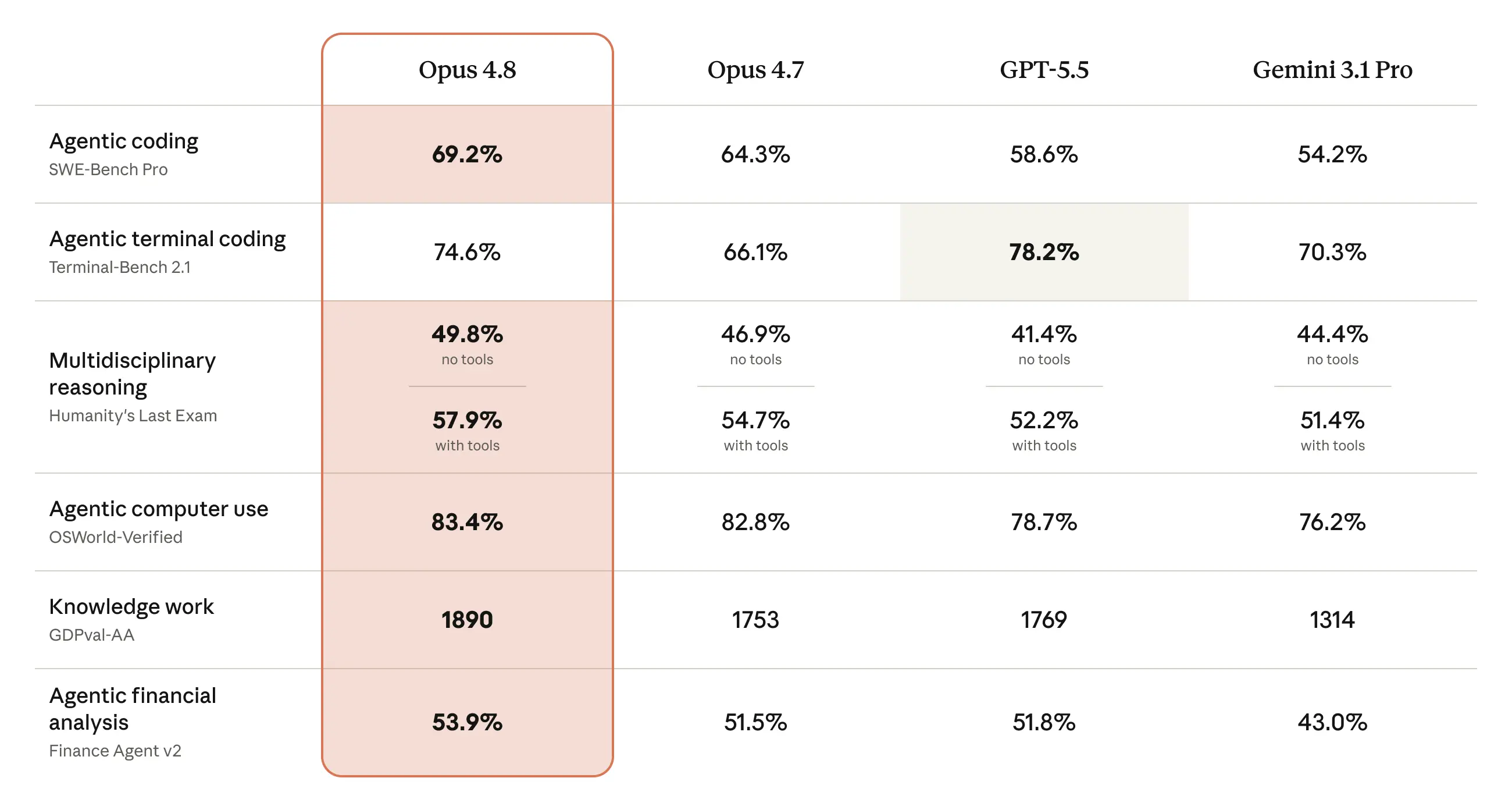
Among the most technically significant claims in the release is Opus 4.8's performance on agentic benchmarks, an area that has become a primary competitive battleground in frontier AI. The model is reported to be the only model to complete every case end-to-end on the Super-Agent benchmark, beating both prior Opus models and GPT-5.5 at cost parity. On Online-Mind2Web, a browser-agent evaluation, Opus 4.8 scored 84%, a meaningful jump over its predecessor and over competing models. On CursorBench, it exceeded prior Opus models at every effort level with more efficient tool calling. These results collectively position Opus 4.8 as a competitive leader in autonomous, multi-step task execution—a capability category increasingly central to enterprise AI adoption.
A notable emphasis in the release is on honesty and calibration. Anthropic reports that Opus 4.8 is approximately four times less likely than Opus 4.7 to allow flaws in its own code to pass unremarked, suggesting meaningful progress on a persistent failure mode in large language models: overconfident or sycophantic outputs that obscure uncertainty. Early testers corroborate this, describing the model as more likely to proactively flag input and output issues rather than leaving them for users to catch. This focus on epistemic reliability reflects Anthropic's broader safety and alignment priorities, which are distinct from raw benchmark performance and have become a differentiating design philosophy for the company.
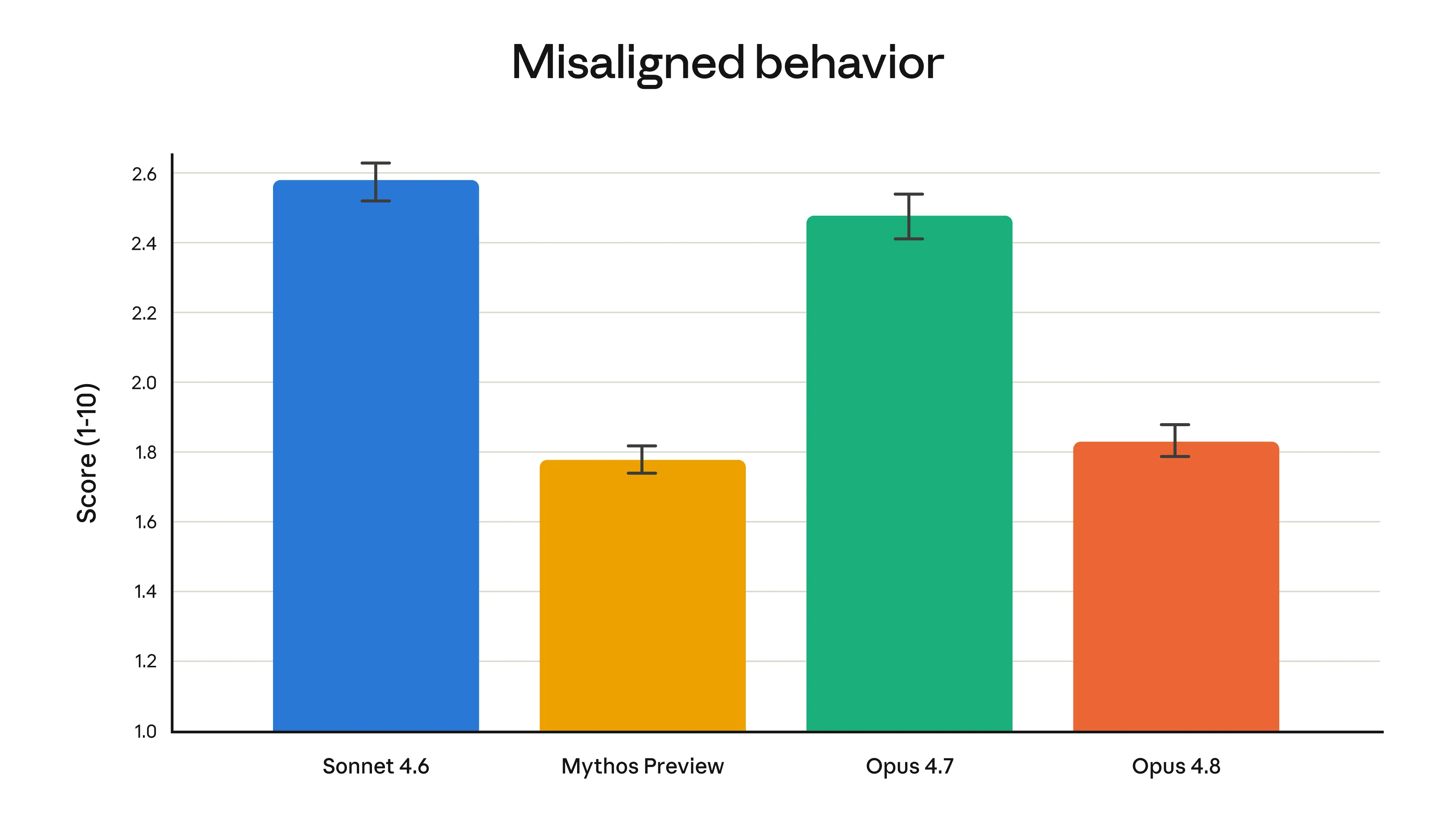
The alignment assessment accompanying the release is also notable. Anthropic's internal alignment team found that Opus 4.8 reaches new highs on prosocial behavioral metrics including support for user autonomy and acting in users' best interests, while exhibiting rates of misaligned behavior—such as deception or cooperation with misuse—substantially lower than Opus 4.7 and comparable to Claude Mythos Preview, described as Anthropic's best-aligned model. The simultaneous improvement in both capability and alignment metrics is significant because these properties are often assumed to be in tension. If verified independently, this would represent a meaningful data point in the ongoing debate about whether safety and capability are fundamentally at odds in large model development.
The Opus 4.8 release fits into a broader pattern of accelerating iterative model deployment across the frontier AI industry, where incremental version updates with targeted improvements in agentic reliability, cost efficiency, and enterprise-specific benchmarks are displacing longer release cycles. Specific gains reported by enterprise partners—Databricks citing 61% cheaper token cost, Hebbia noting better citation precision in financial document workflows, and legal AI firms reporting the first model to break 10% on an all-pass legal agent standard—illustrate how model improvements are increasingly evaluated through vertical-specific lenses rather than general-purpose benchmarks alone. This signals a maturing market in which differentiation is won at the application layer, and where model developers must demonstrate value in concrete professional workflows to maintain enterprise adoption.












 Read original article →
Read original article →