Detailed Analysis
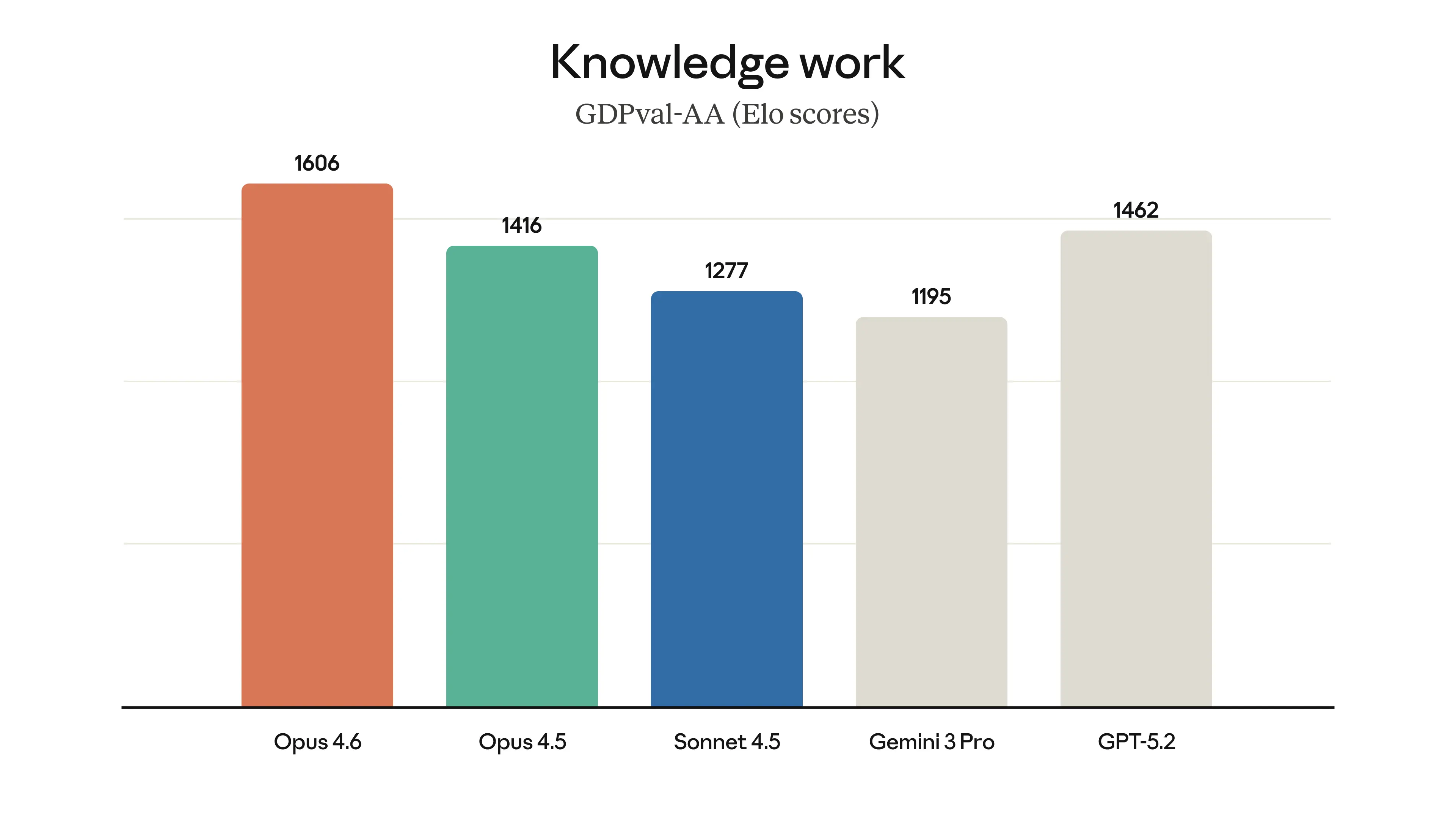
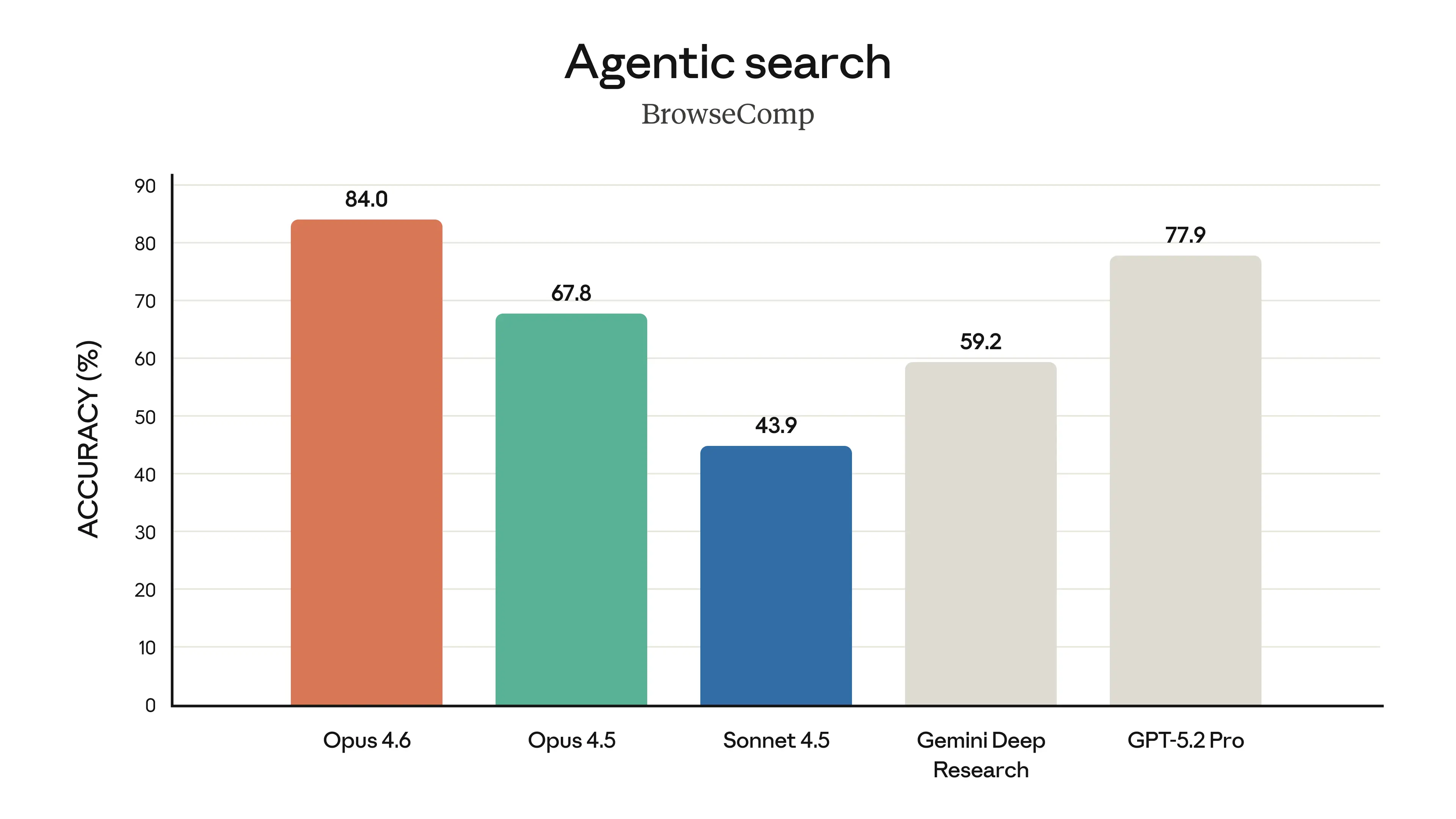
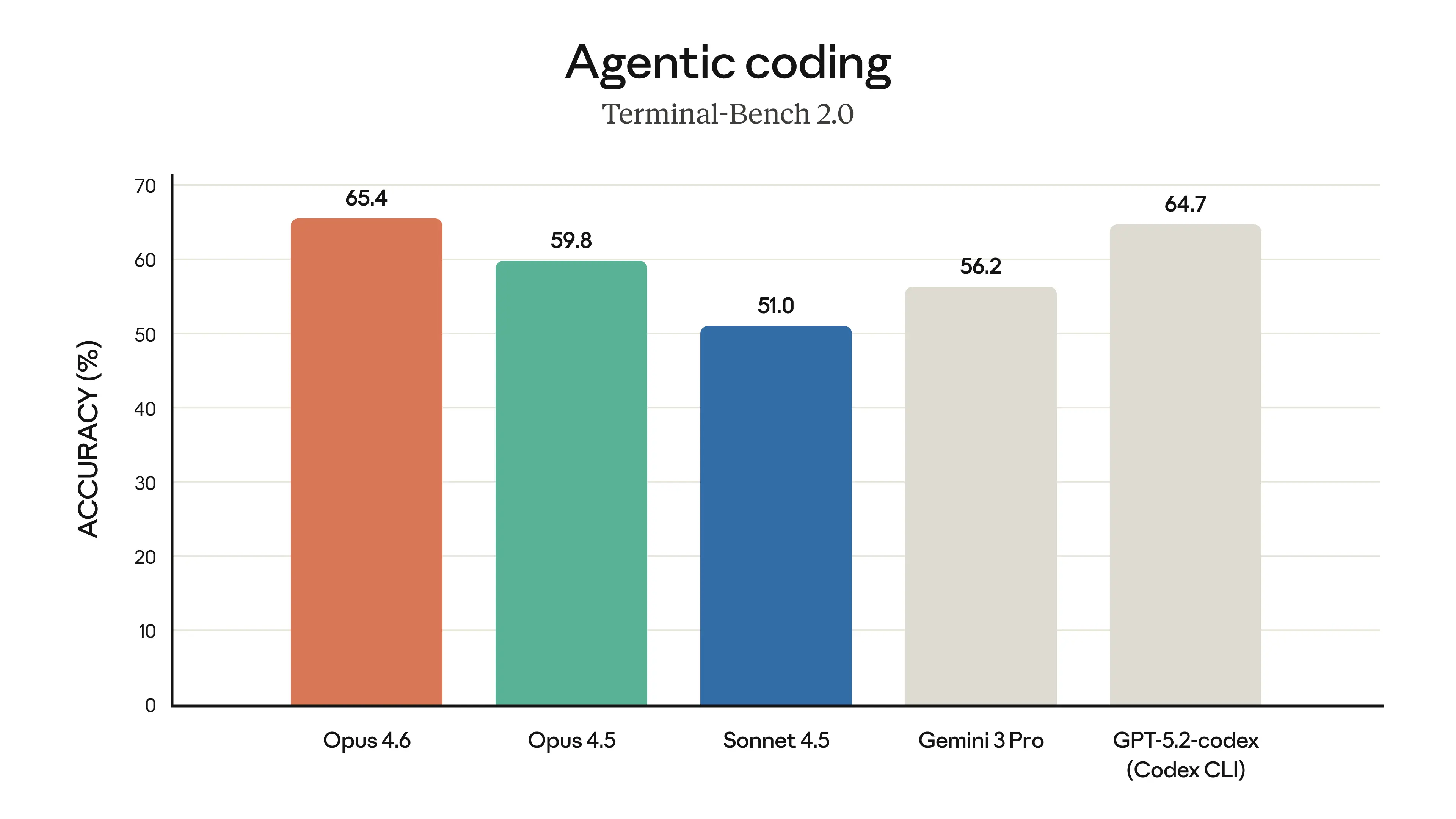
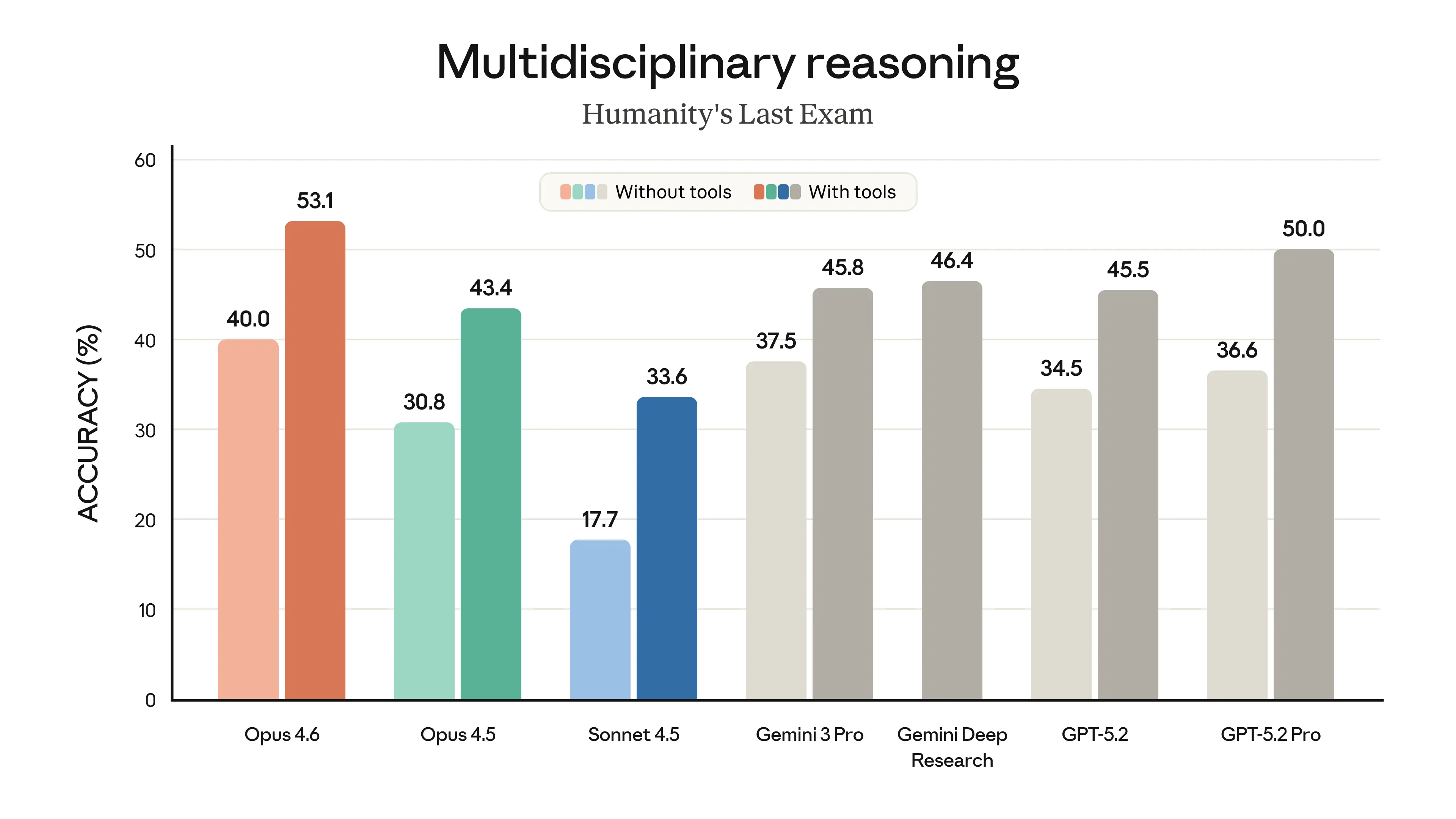
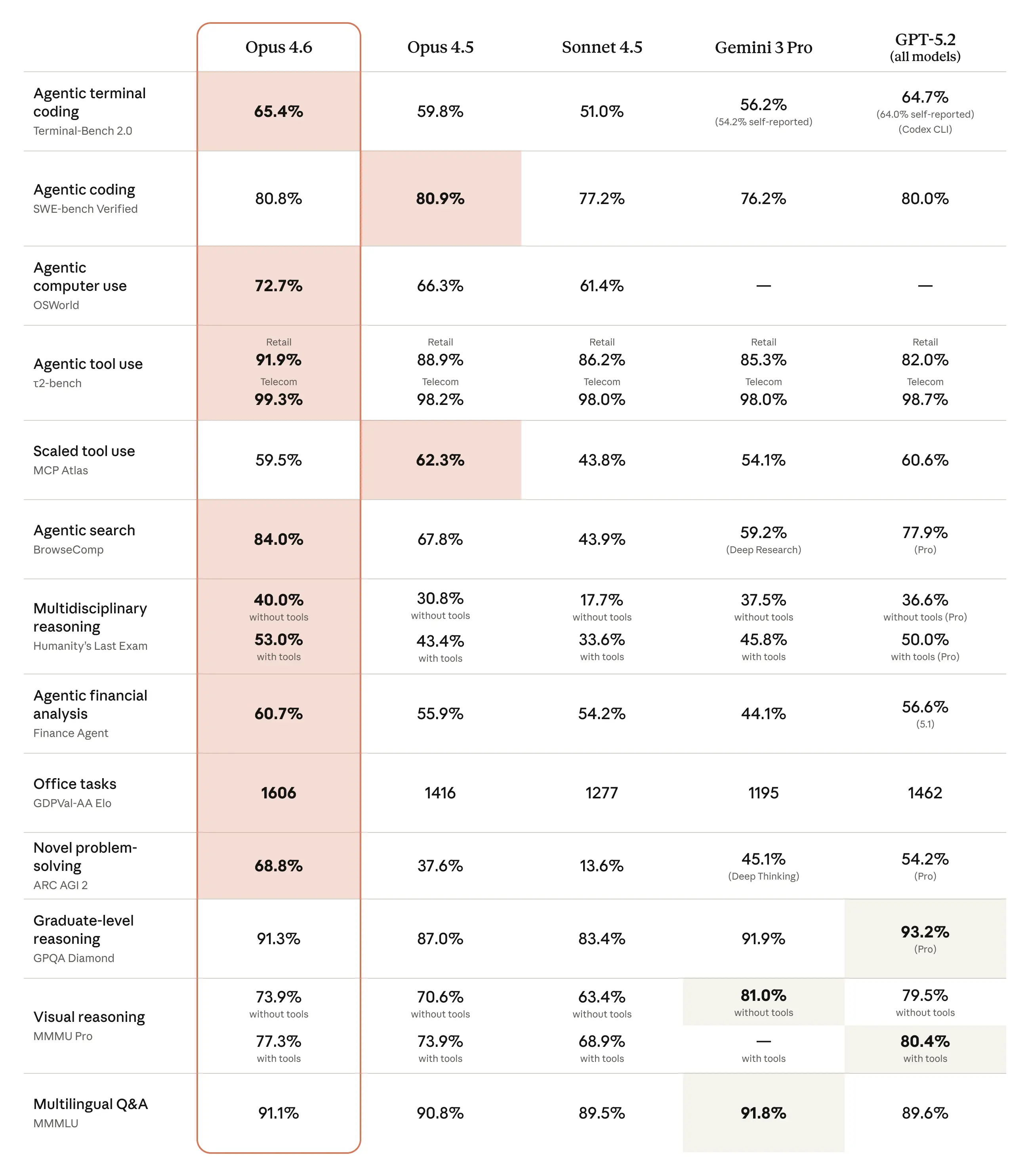
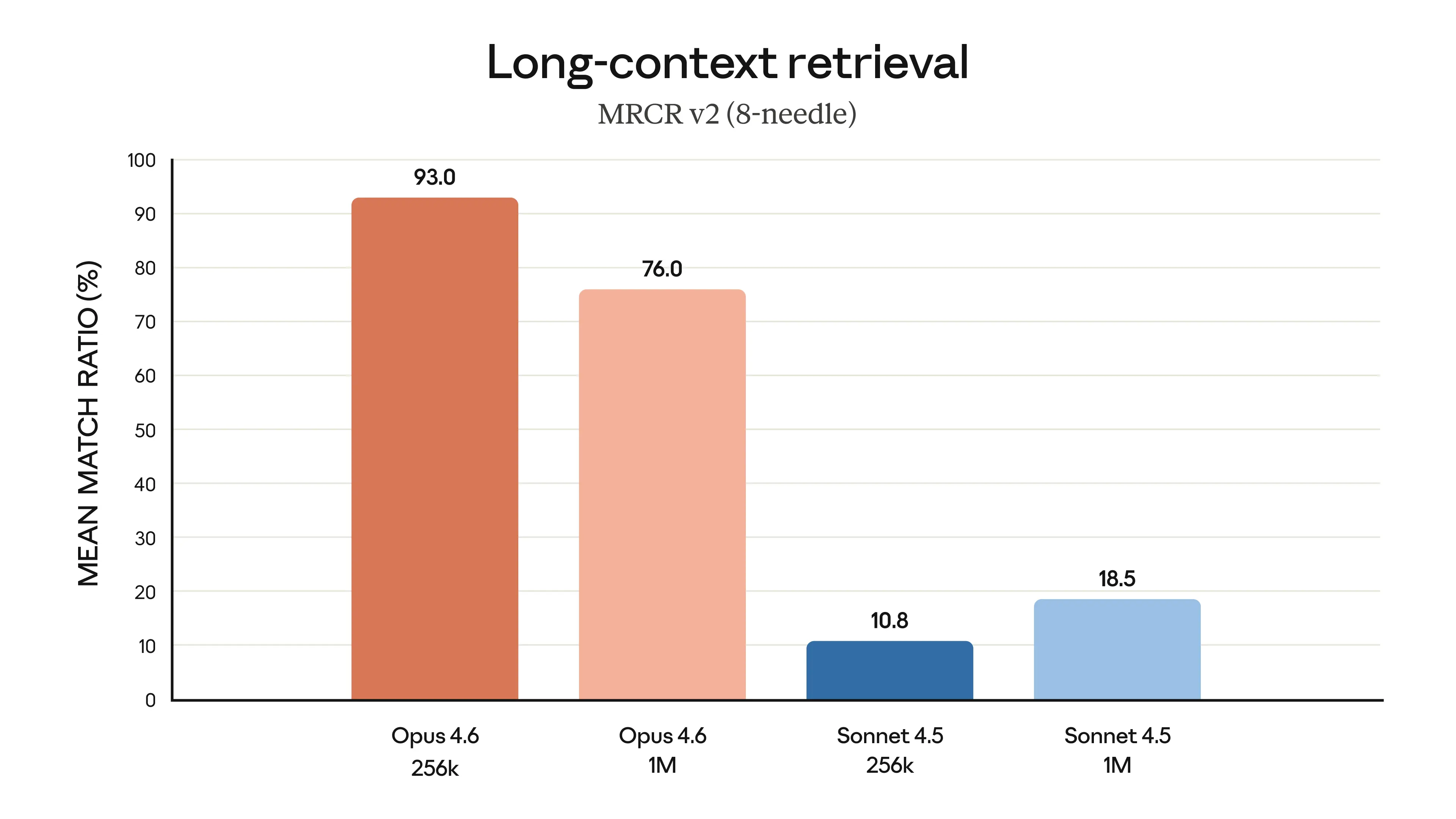
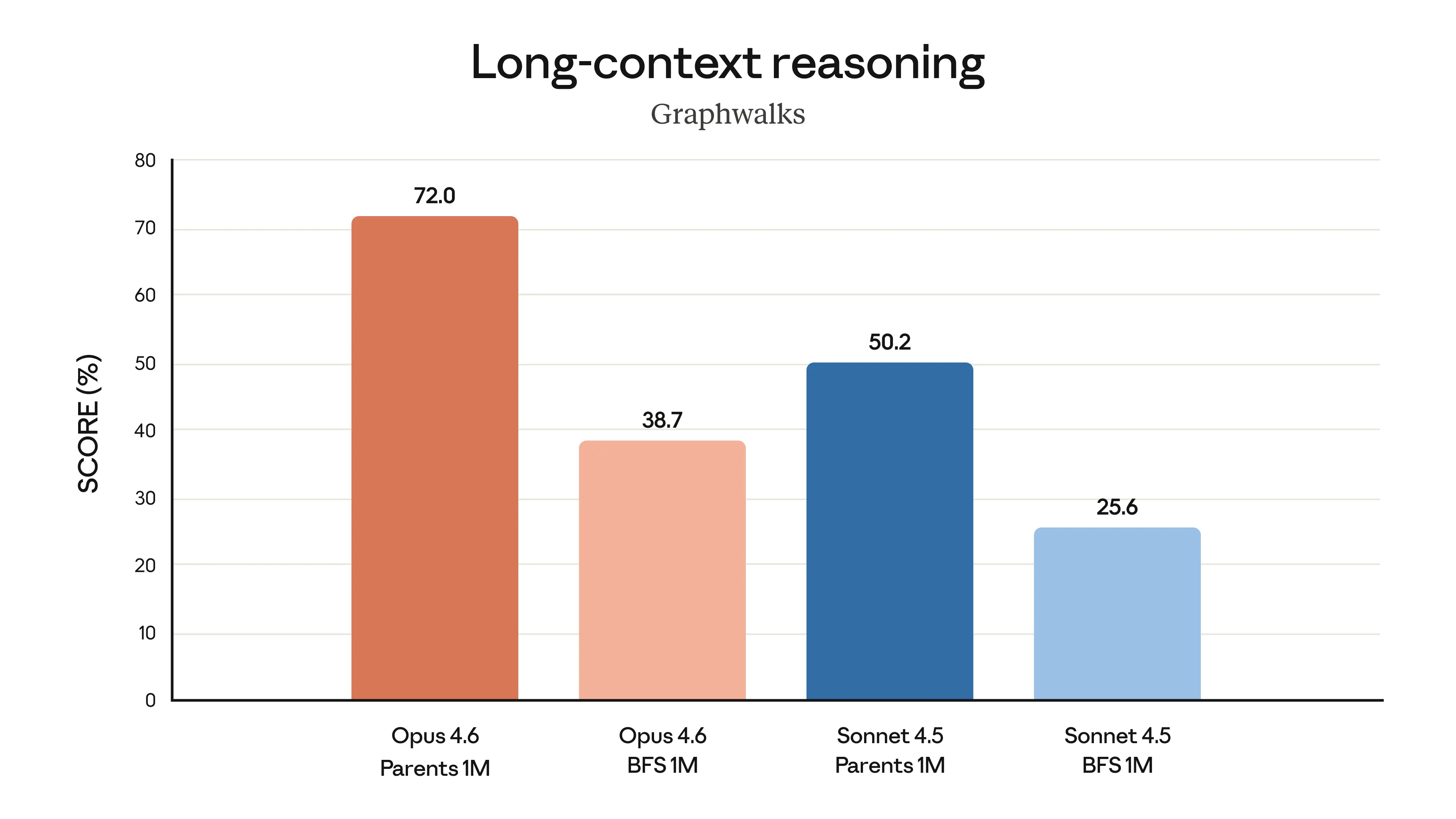
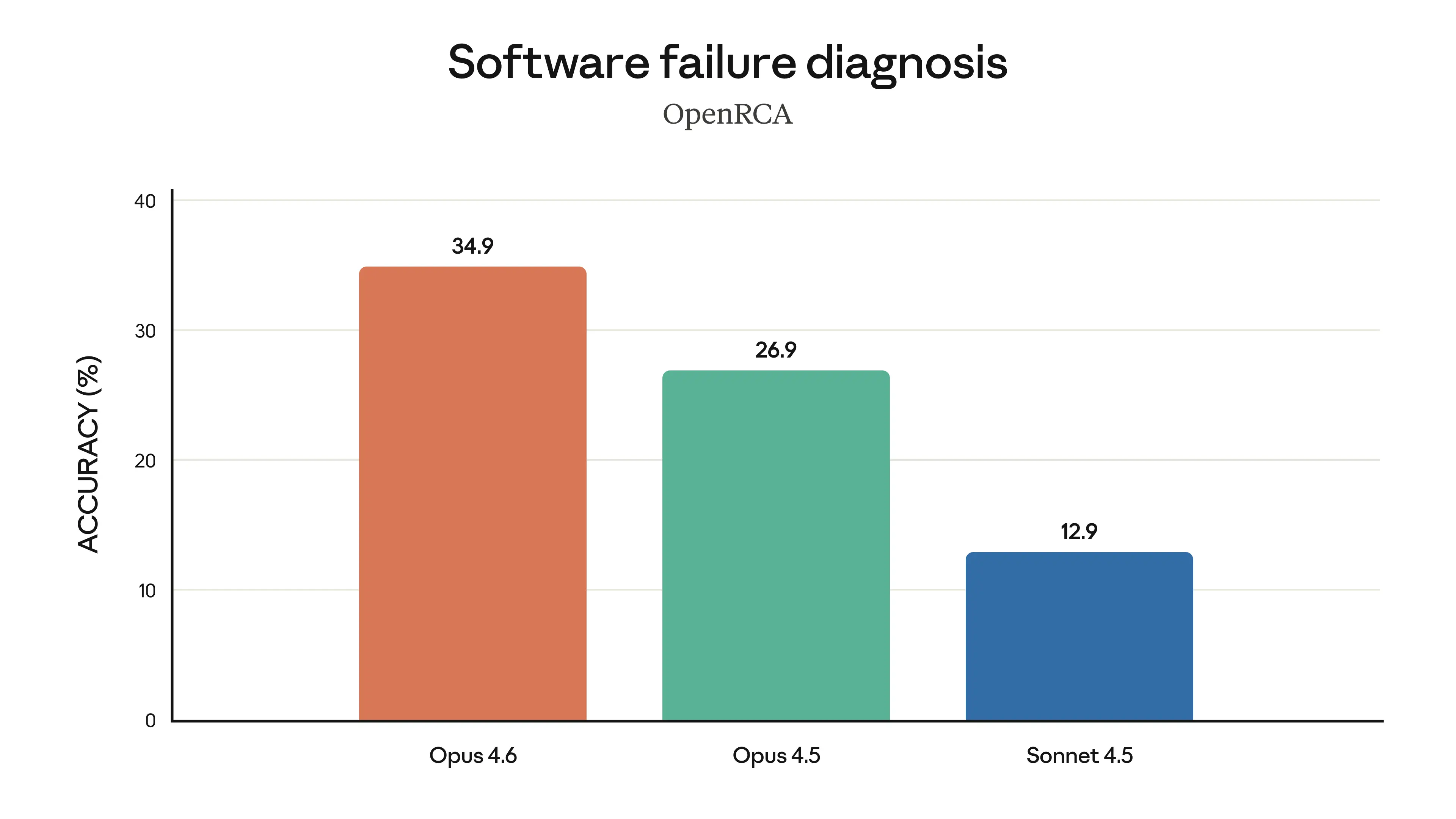
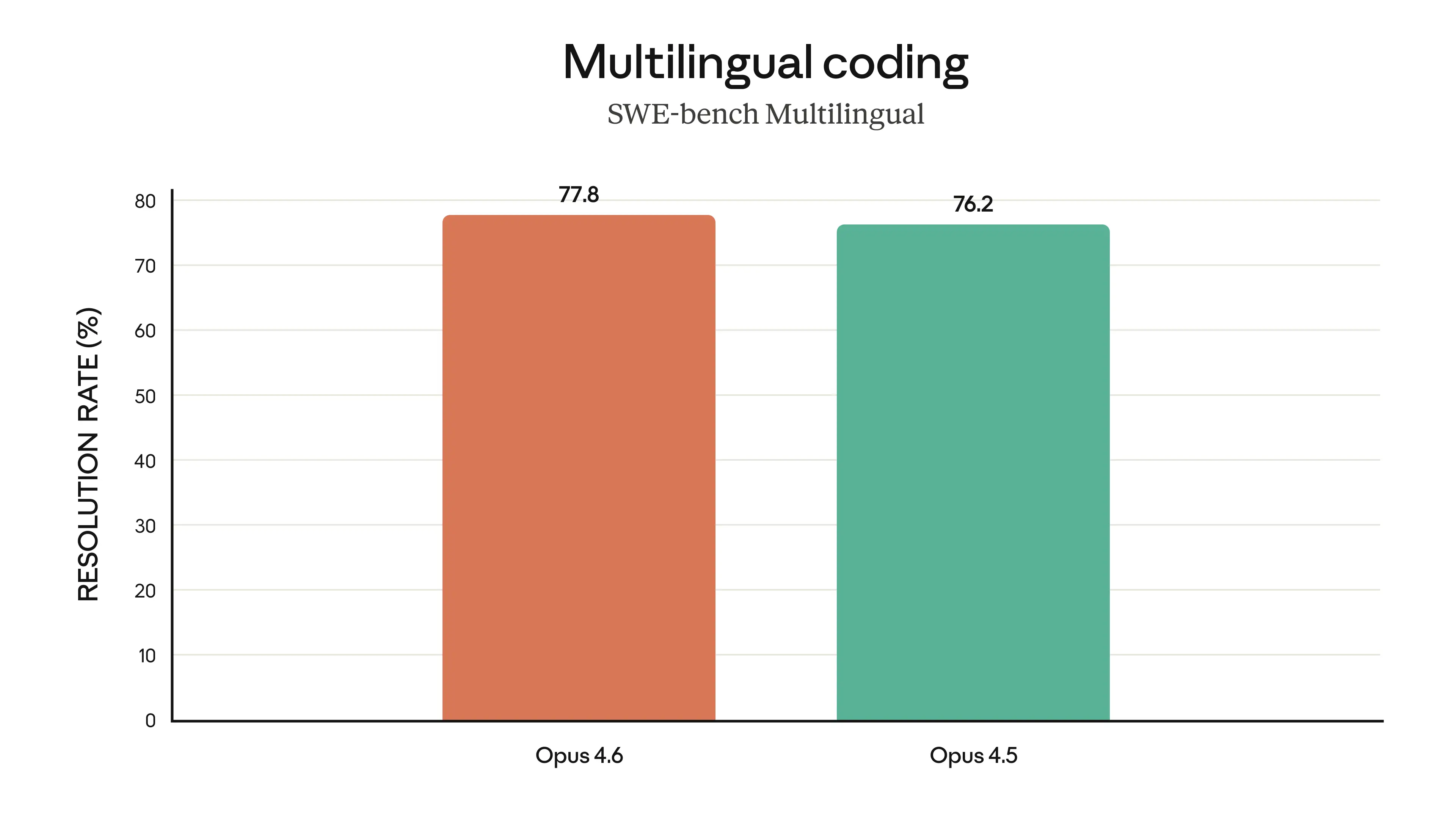
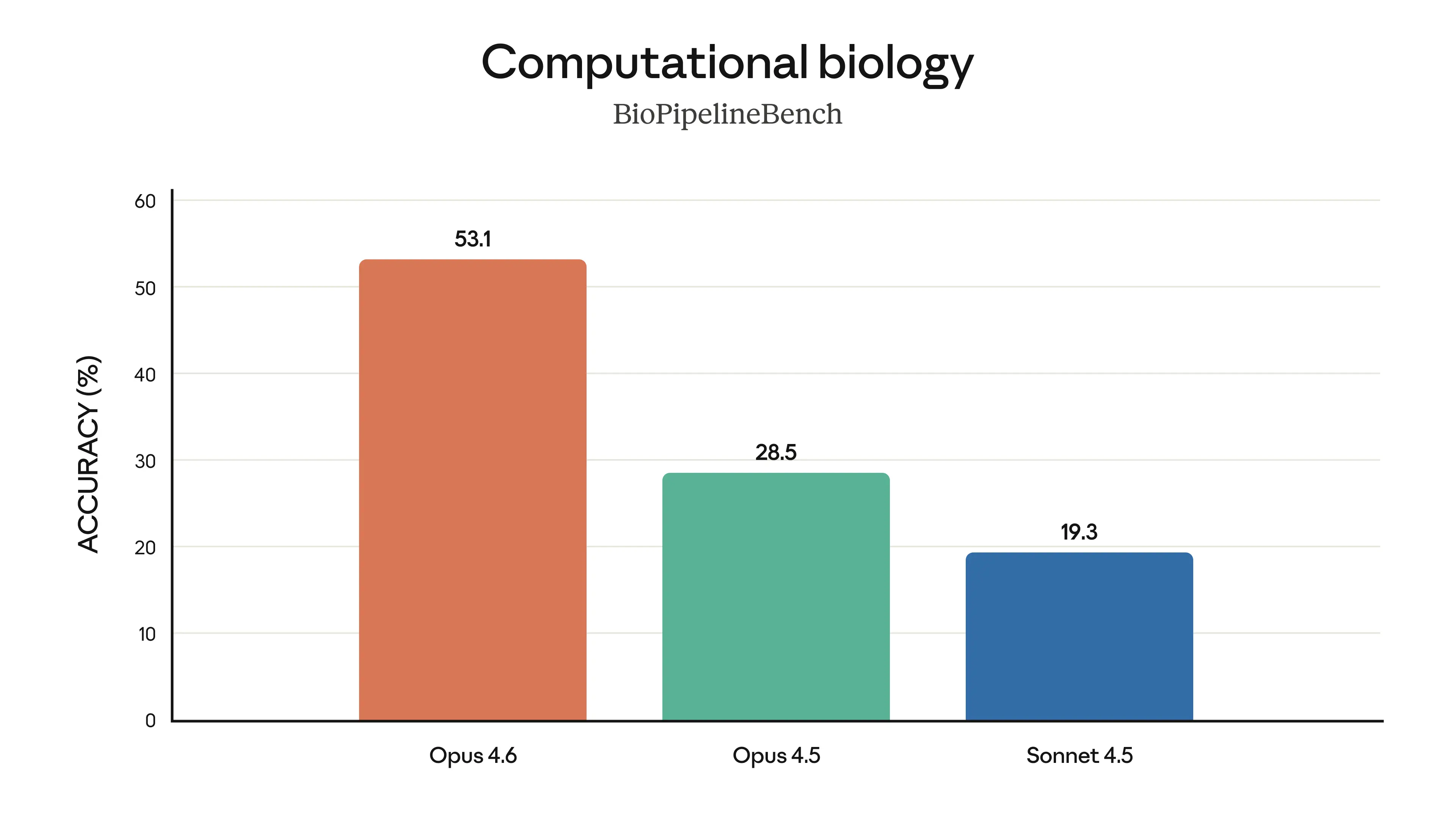
Claude Opus 4.6 represents Anthropic's most capable model release to date, delivering substantial upgrades across coding, agentic task performance, long-context reasoning, and knowledge work. The model introduces a 1 million token context window in beta — a first for the Opus model class — and achieves state-of-the-art results on several demanding evaluations, including Terminal-Bench 2.0 for agentic coding, Humanity's Last Exam for complex multidisciplinary reasoning, and BrowseComp for locating hard-to-find information online. On GDPval-AA, an evaluation measuring performance on economically valuable knowledge work in finance, legal, and other professional domains, Opus 4.6 outperforms OpenAI's GPT-5.2 by approximately 144 Elo points and surpasses its immediate predecessor, Claude Opus 4.5, by 190 points. Pricing remains unchanged at $5/$25 per million input/output tokens, positioning the release as a significant capability jump without an increase in cost to developers.
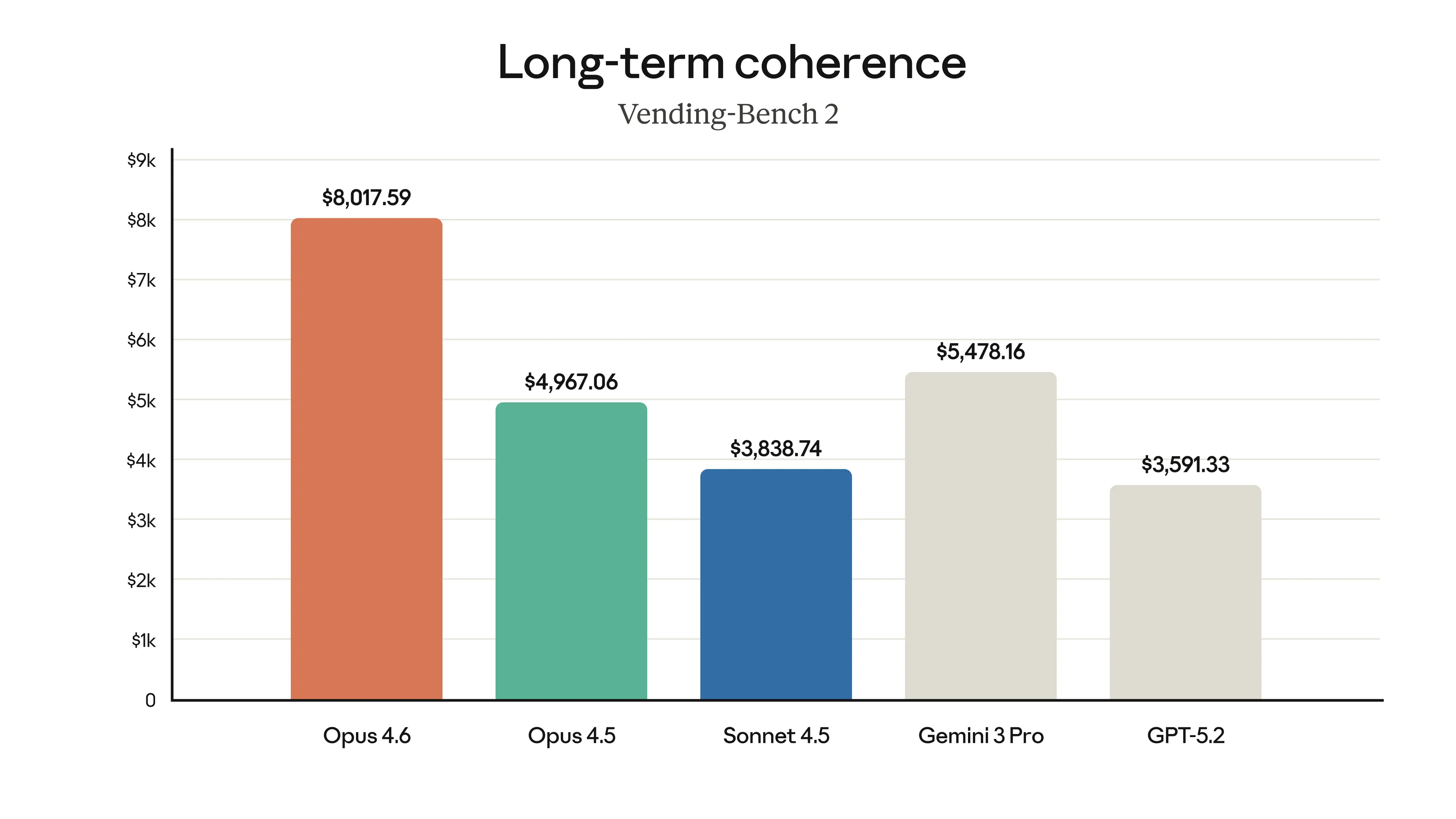
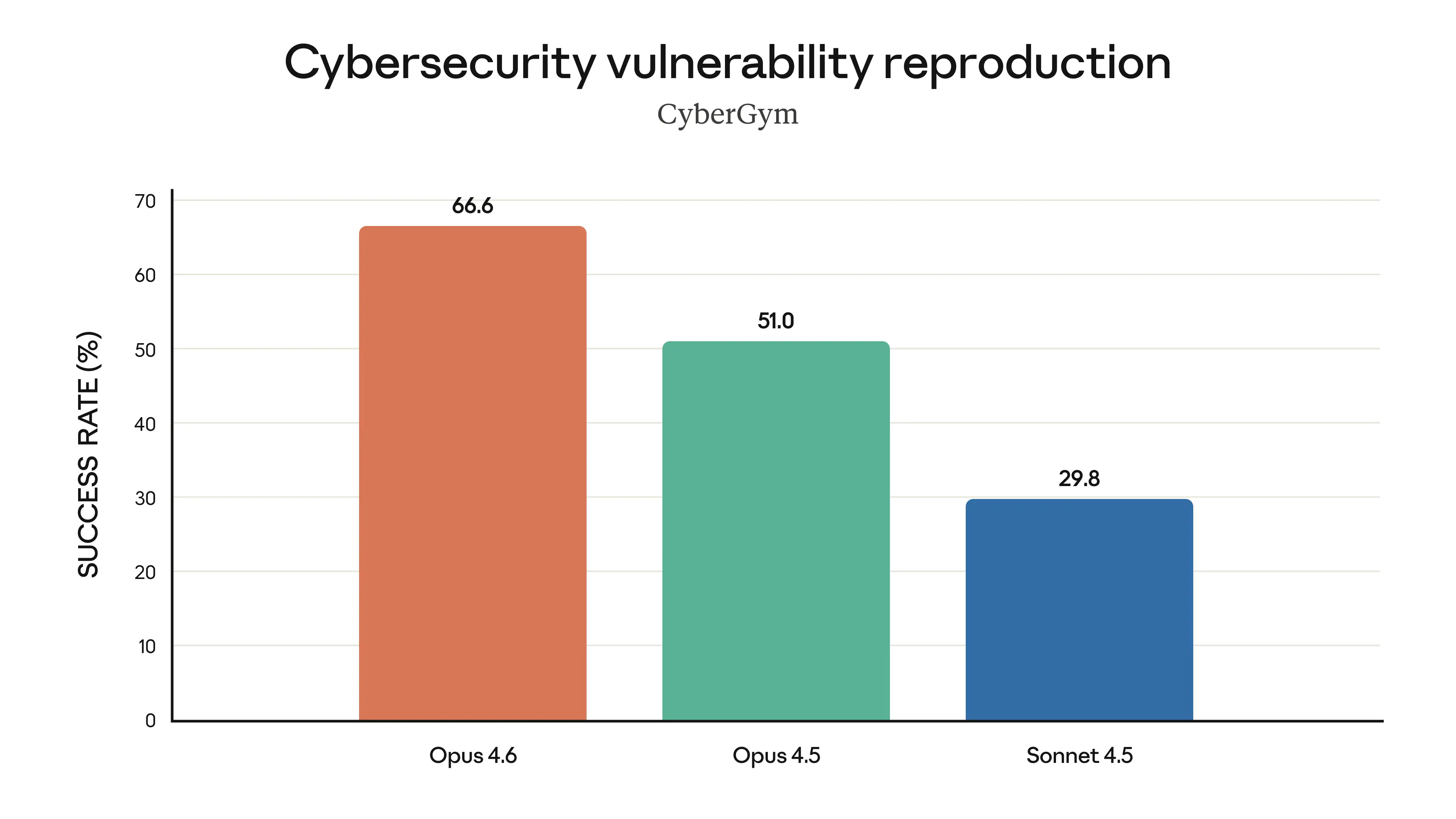
The release is distinguished by its emphasis on agentic reliability — the model's ability to sustain complex, multi-step tasks over longer sessions without human intervention. Early Access partners, including Notion, Windsurf, and Cognition (makers of the Devin platform), reported that Opus 4.6 breaks complex requests into concrete subtasks, runs tools and subagents in parallel, and identifies blockers with greater precision than prior models. In cybersecurity investigation workflows, one partner reported that Opus 4.6 produced superior results in 38 out of 40 blind trials against Claude 4.5 models running identical agentic harnesses with up to nine subagents and over 100 tool calls. These results reflect a qualitative shift in how the model approaches ambiguity and extended reasoning — reportedly thinking longer and revisiting its reasoning before committing to an answer, a behavior Anthropic acknowledges can increase latency on simpler tasks and for which it has introduced new effort controls via an `/effort` parameter.
Alongside the model itself, Anthropic is shipping a suite of infrastructure and product upgrades designed to operationalize Opus 4.6's capabilities at scale. Claude Code gains the ability to coordinate agent teams working in parallel on shared tasks. API users gain access to context compaction, which allows the model to summarize its own context window to continue long-running tasks without hitting token limits. Adaptive thinking enables the model to self-calibrate how much extended reasoning to apply based on contextual cues. On the productivity side, Anthropic is announcing substantial upgrades to Claude in Excel and releasing Claude in PowerPoint in research preview, deepening integration with the tools professionals use daily and aligning with the broader Cowork product vision of autonomous multitasking on behalf of users.
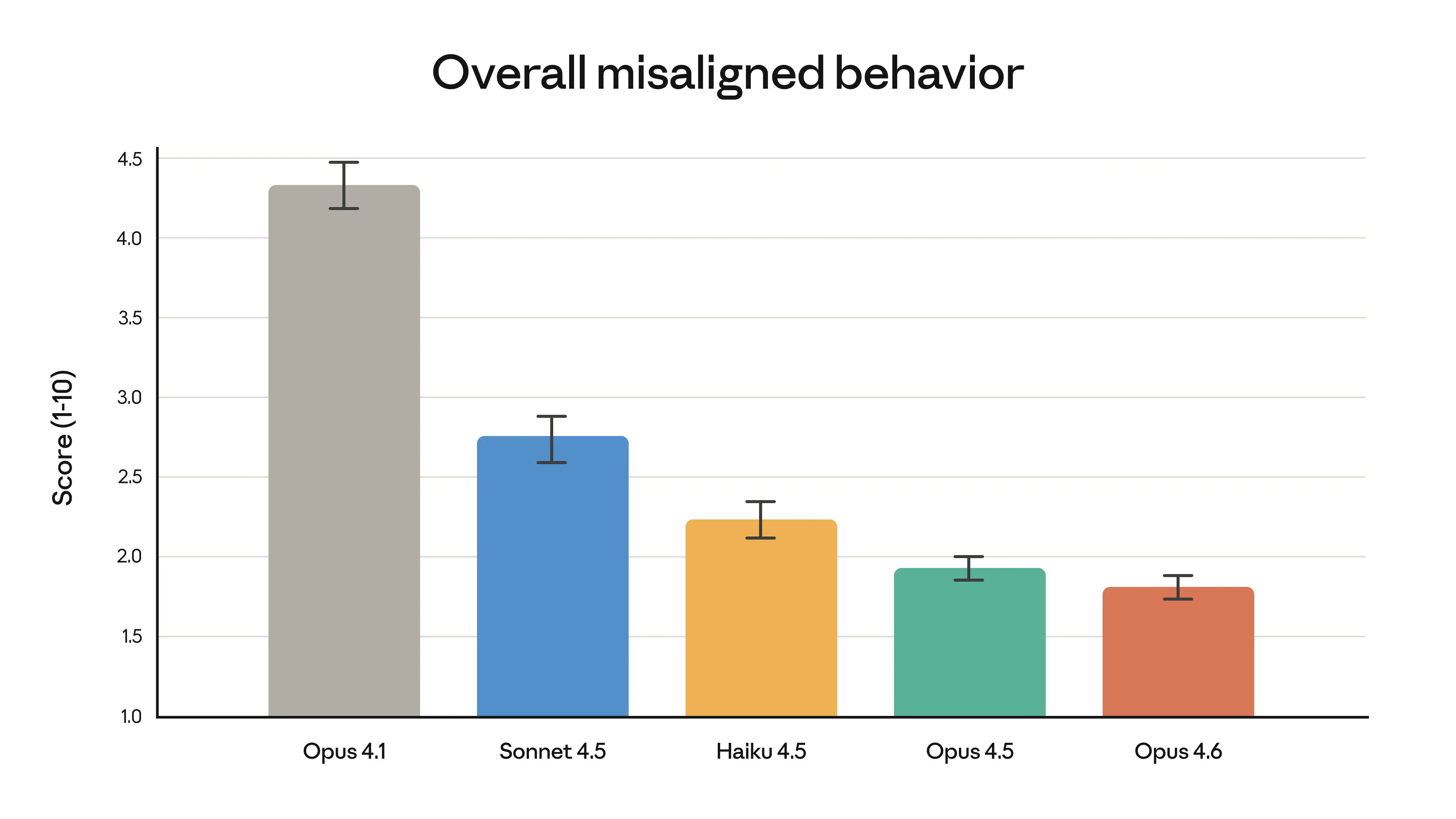
The release reflects several converging trends shaping frontier AI development in 2026. First, the competition between Anthropic and OpenAI is increasingly being measured not just on benchmark scores but on domain-specific, economically grounded evaluations like GDPval-AA — a signal that the industry is maturing past generic capability tests toward measuring real-world professional value. Second, the expansion of context windows to 1 million tokens mirrors a broader race among frontier labs to support the kind of sustained, document-heavy workflows that enterprise customers demand, and which shorter context models struggle to support reliably. Third, Anthropic's framing of Opus 4.6 as a safe model — accompanied by an extensive system card and claims of low misaligned-behavior rates — underscores the company's ongoing effort to position safety not as a constraint on capability but as a co-equal design goal. That Anthropic builds and tests its own models using Claude Code and internal agentic workflows creates a feedback loop in which the company serves as both developer and early customer, a practice that increasingly distinguishes labs building deeply integrated AI development toolchains from those treating models as standalone products.






















 Read original article →
Read original article →