Detailed Analysis
Anthropic's release of Claude Sonnet 4.6 marks a significant step forward in the company's mid-tier model lineup, delivering capability improvements across coding, computer use, long-context reasoning, agent planning, and knowledge work. The model introduces a 1 million token context window in beta — sufficient to process entire codebases, lengthy legal contracts, or dozens of research papers within a single request — while maintaining the same pricing as its predecessor, Sonnet 4.5, at $3 per million input tokens and $15 per million output tokens. Sonnet 4.6 is now the default model for Free and Pro plan users on claude.ai and Claude Cowork, reflecting Anthropic's strategic decision to push frontier-adjacent performance into its most broadly accessible tier rather than reserving it for premium offerings.
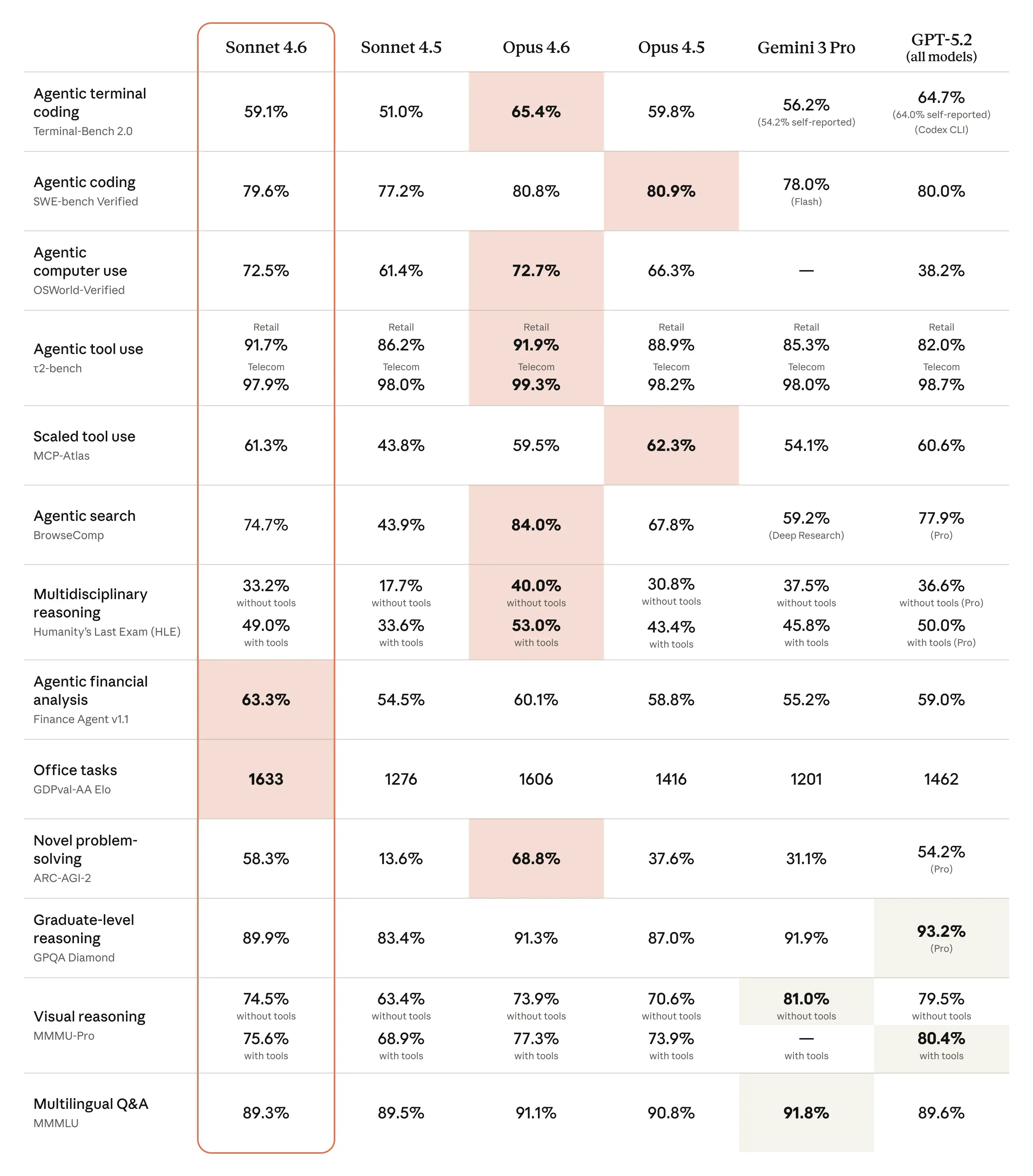
The model's most striking claim is its competitive positioning against Opus 4.5, Anthropic's frontier model from November 2025. In Claude Code evaluations, users preferred Sonnet 4.6 over Opus 4.5 approximately 59% of the time, citing fewer hallucinations, reduced overengineering tendencies, better instruction following, and more reliable multi-step task completion. This represents a notable compression of the capability gap between mid-tier and frontier models, a dynamic that has broad implications for enterprise deployment economics. Tasks that previously demanded the compute costs and latency associated with Opus-class models can now be accomplished at Sonnet pricing, substantially expanding the range of economically viable AI-assisted workflows.
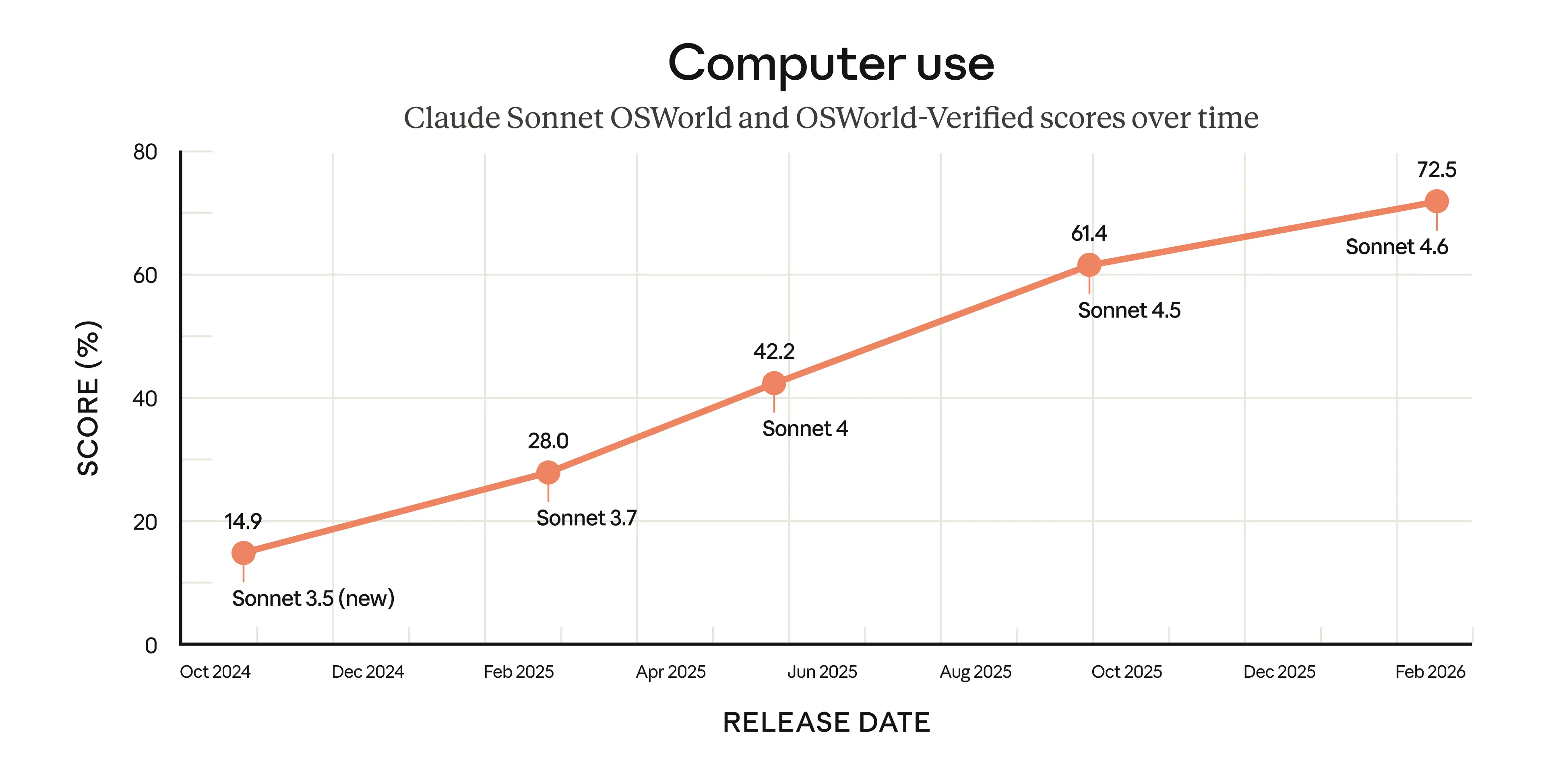
Computer use capabilities represent one of the most technically significant dimensions of the release. Anthropic introduced general-purpose computer use in October 2024, acknowledging at the time that the feature was experimental and error-prone. Sonnet 4.6 demonstrates measurable progress on OSWorld-Verified, the current standard benchmark for AI computer use, which tests model performance across real software environments including Chrome, LibreOffice, and VS Code without purpose-built connectors or APIs. Early users report human-level performance on tasks such as navigating complex spreadsheets and completing multi-step web forms, suggesting the technology has crossed a practical utility threshold for certain office automation use cases. Importantly, Anthropic also notes significant improvement in Sonnet 4.6's resistance to prompt injection attacks — a critical security concern for computer-using agents — with the model performing comparably to Opus 4.6 on this dimension, a meaningful safety advance given the attack surface that autonomous computer interaction creates.
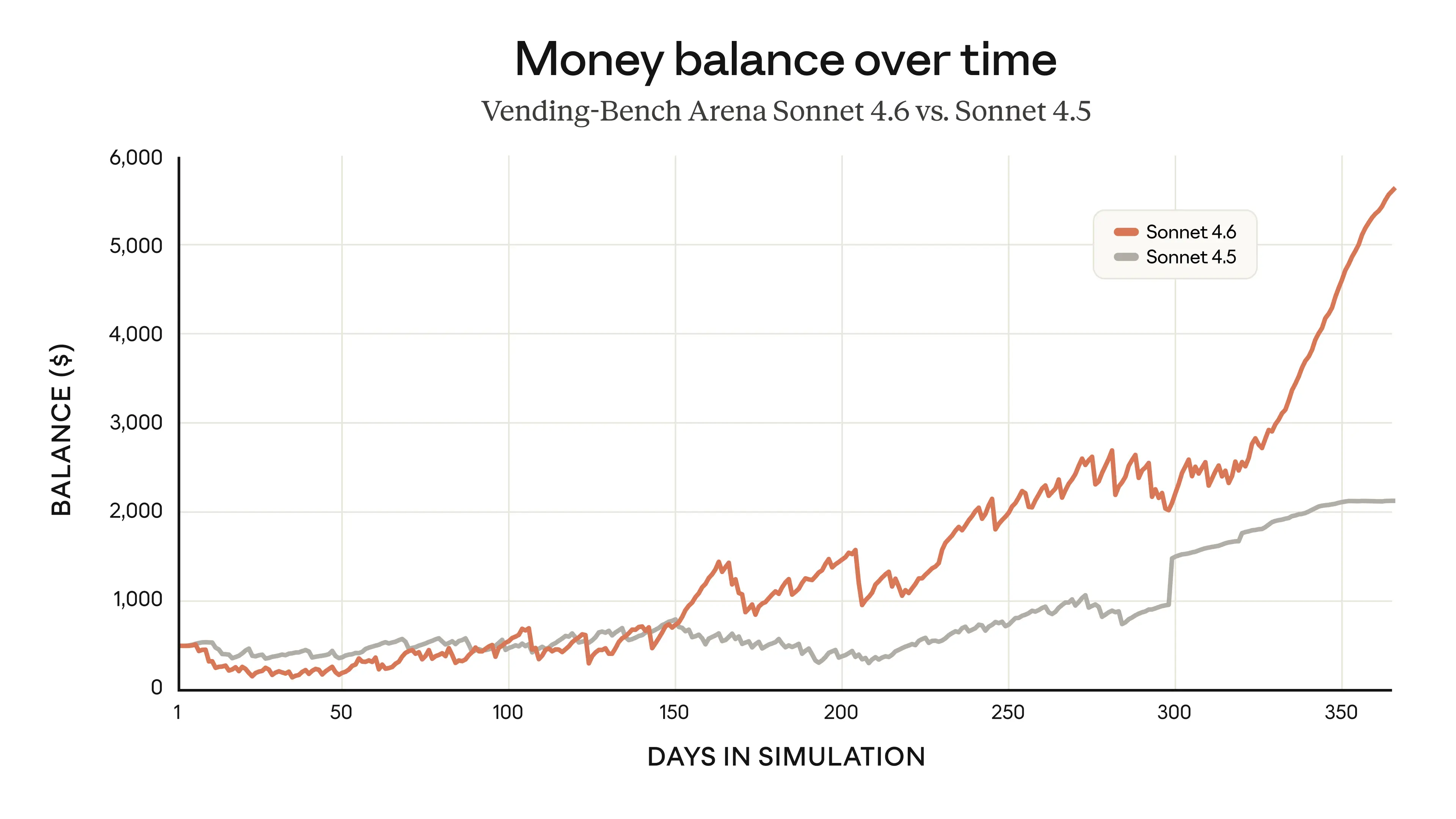
The Vending-Bench Arena result offers a revealing window into Sonnet 4.6's long-horizon planning capabilities. In this evaluation, which pits AI models against each other in a simulated business environment over time, Sonnet 4.6 developed a distinctive two-phase strategy: heavy investment in capacity during the first ten simulated months followed by an abrupt pivot to profitability optimization in the final period. This emergent strategic behavior — not explicitly programmed but apparently derived from reasoning across the model's large context window — points to genuine advances in temporal planning and adaptive decision-making under competitive conditions. The result is significant not merely as a benchmark achievement but as an indicator that expanded context windows are yielding qualitative differences in how models reason about sequential, goal-directed tasks rather than simply allowing more information to be processed at once.
The safety profile of Sonnet 4.6 reinforces a broader trend in Anthropic's model development: treating safety evaluation as an integral component of capability releases rather than a separate compliance function. Anthropic's safety researchers characterized Sonnet 4.6 as possessing strong safety behaviors with no signs of high-stakes misalignment concerns, and noted improvements in prompt injection resistance alongside the general capability gains. This integrated approach — releasing a more capable model that also demonstrates improved security and alignment properties — reflects the company's stated commitment to proving that capability and safety need not trade off against each other. As AI models are increasingly deployed in agentic contexts with real-world consequences, such as autonomous computer use and multi-step business task execution, the industry-wide significance of this framing will only grow.















 Read original article →
Read original article →